LSM Trees
From
Book
Designing Data-Intensive Applications > Ch3 Storage:
- Writes are added to an in-memory sorted structure (memtable).
- Write this out to disk as an SSTable when it gets too big and start with an empty memtable.
- Compact & merge the SSTables offline.
- Reads start with the memtable and then go up the (stack of) SSTables in recency order.
- Reading an absent key has to traverse the entire tree (reading each SSTable from disk)
- Implementations may use Bloom Filters to fast-exit in this case.
- Need to write to a WAL before a write is successful to guard against crashes before the memtable is flushed.
- Used in LevelDB/RocksDB.
Book
Designing Data-Intensive Applications hand-waves away the actual implementation details of data layout and compaction strategies (what makes an LSM-Tree a Tree, essentially); here’s more info from the RocksDB wiki:
Compaction Strategies
https://github.com/facebook/rocksdb/wiki/Compaction
-
-
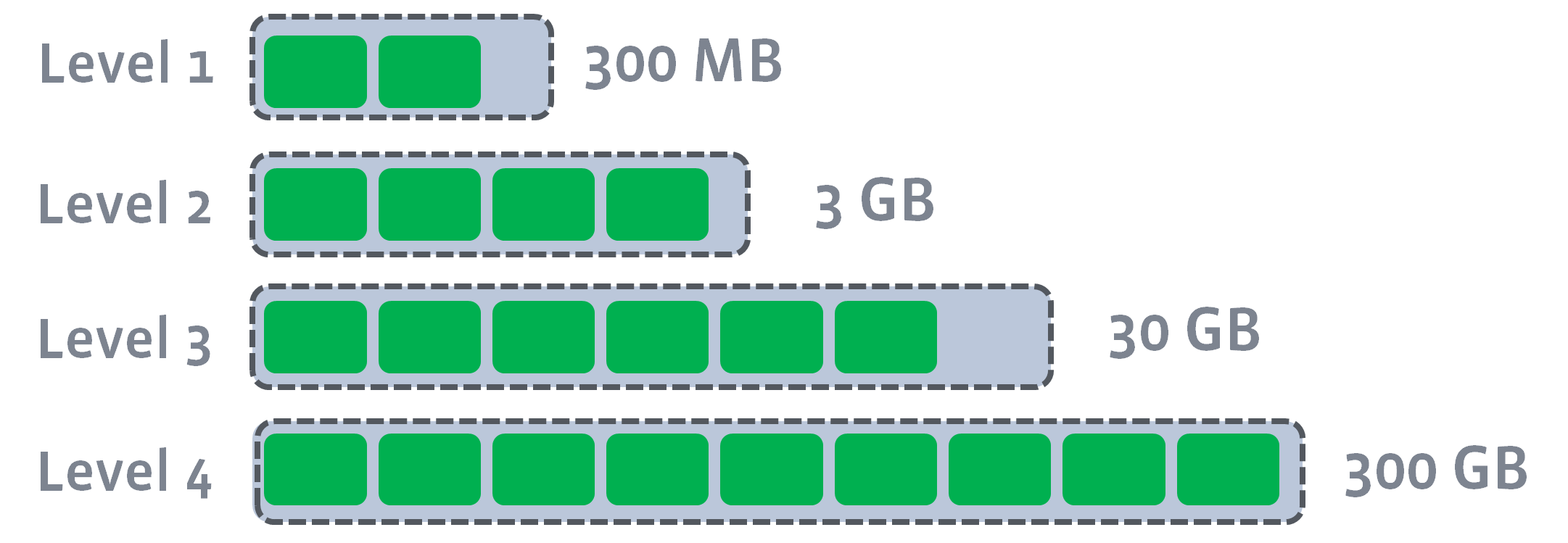
- SSTables are stored in a number of levels.
- Each level (except level 0) is a single sorted run that is split into many files.
- Each level is many times larger than the previous level.
- Data from the memtable is flushed to level-0; this level necessarily contains SSTables with overlapping keys
- When level-0 becomes larger than a threshold, all its SSTables are merged into all the SSTables from level 1 that contain overlapping keys.
- The new SSTables thus formed along with SSTables from level 1 that weren’t part of the merge become the new level 1.
- This may happen recursively, so write amplification is a concern.
-
-
Leveled-N
- It allows more than one sorted run per level.
- Compaction merges all sorted runs from level $L{n-1}$ into one sorted run from $Ln$, which is leveled.
- More read amplication, lower write amplification.
-
- Compaction merges all sorted runs in one level to create a new sorted run in the next level.
- Each level has $N$ sorted runs. Each sorted run is $N$ times larger than sorted runs in the previous level.
- Compaction does not read/rewrite sorted runs in Ln when merging into Ln.
- If I understand currently, this is different from Leveled-N in that destination levels only have new SSTables attached, but never rewritten.
- Tiered compaction minimizes write amplification at the cost of read and space amplification.
- This is an interesting point that I need to think about some more:
A common approach for tiered is to merge sorted runs of similar size, without having the notion of levels (which imply a target for the number of sorted runs of specific sizes). Most include some notion of major compaction that includes the largest sorted run and conditions that trigger major and non-major compaction. Too many files and too many bytes are typical conditions.
-
Tiered+Leveled
- Lower levels are leveled, and higher levels are tiered
- Optimize for lower read amplification + higher write amplification at lower levels and the opposite at higher levels
- Lower levels are read more often than higher levels and are smaller, so write amplification has a smaller impact