Designing Data-Intensive Applications
Ch1: Reliable, Scalable, and Maintainable Applications
- Twitter started with a write-optimized approach - posted tweets would be written once and readers would JOIN to fetch the correct tweets
- This was untenable because of read volume (300k/sec vs. 4.6k/sec for writes) and so they switched to optimizing for reads. Writers write to each user/reader’s inbox; this fanout amplifies writes from 4.6k/sec to 345k/sec on average. Worst case is tens of millions of writes against a single posted tweet.
- They’re now (as of publication) moving to a hybrid approach. Use read-optimized for most people, but use the write-optimized approach for users with millions of followers - merge results at read time.
Latency and response time are often used synonymously, but they are not the same. The response time is what the client sees: besides the actual time to process the request (the service time), it includes network delays and queueing delays. Latency is the duration that a request is waiting to be handled—during which it is latent, awaiting service
- Not sure I’ve ever seen this definition; my understanding is that latency is the time it takes for a request to traverse your system, during which the client is latent. 🤔
Ch3: Storage
- SSTable: on-disk log segment (k/v) that is sorted by key, and typically uses a sparse in-memory (hash) index for (point & range) lookups. Can be compacted. Typically at least a few megabytes in size.
- LSM-Tree:
- Writes are added to an in-memory sorted structure (memtable). Write this out to disk as an SSTable when it gets too big and start with an empty memtable. Compact & merge the SSTables offline.
- Reads start with the memtable and then go up the (tree of) SSTables in recency order. Used in LevelDB/RocksDB.
- Reading an absent key has to traverse the entire tree (reading each SSTable from disk), so db implementations may use Bloom Filters to fast-exit in this case.
- Need to write to a WAL before a write is successful to guard against crashes before the memtable is flushed.
- I can’t think of a reason LSM DBs need to use locks except to synchronize access to the memtable. Is this true?
- B-Tree:
- uses fixed-size blocks that are typically 4kB in size. All reads and writes happen at the block level. Every block (and its children) is responsible for a continuous range of keys.
- The blocks form a tree; each block references children blocks with on-disk pointers, using markers to delimit the range that that child contains data for.
- The number of pointers per block is the branching factor. A B-Tree with 4kB blocks and a branching factor of 500 can store 256TB in 4 levels (!).
- When a block is full, it is split into two non-full blocks and the parent is updated (which means overwrites) so it uses two pointers for that range. I assume this is recursive. This keeps the B-Tree balanced during writes. A WAL is maintained for crash recovery. LMDB eschews a WAL by using copy-on-write to copy all modified pages, resulting in a new root.
- Reads and writes are relatively easy, deletes are more complicaed.
- The split operation can’t be performed offline, so concurrency control is required.
- A key is normally paired with a value, regardless of it’s position in the tree. A variation called a B+ tree keeps all values in leaf nodes, any keys found at higher levels are duplicated. This is typically the default because it allows for a higher branching factor.
Ch5: Replication
- Leader, multi-leader, leaderless
- Replication types
- Statement-based: non deterministic statements can produce different results
- WAL shipping: can be coupled to the underlying disk format, including potentially disk block offsets. Also might be coupled to a particular dB version, making upgrades tricky.
- Logical log shipping: a version of the WAL that’s at a higher level of abstraction (rows that were added/deleted/etc.)
- Trigger based replication: more overhead, but possibly a good fit if only a subset of data needs to be replicated
- Low-write/high-read systems can use a single leader for writes, but scale reads almost infinitely by adding read-replicas. Almost certainly needs to be async replication though.
- Issues with (async) replication lag in a single-leader setup:
- Reading your own writes (mitigated by carefully routing read requests that might fall into this category to the leader
- Reads are possibly non-monotonic (can appear to go backwards in time). Can be mitigated somewhat by pinning a replica for reads.
- Writes can be replicated out-of-order, especially in sharded/multi-leader systems. Eventual consistency does not imply ordering consistency, only causal consistency does.
- Multi-leader
- One leader per datacenter
- Writes propagated between leaders need conflict resolution
- An app with a local db that syncs up when offline could be thought of as multi-leader, and also need conflict resolution (the same doc is edited on two devices offline and both devices are then brought online)
- Examples: DynamoDB global tables, Aurora, mySQL, pg
- Conflict resolution (multi-leader)
- Last-write-wins (LWW) - easy, but prone to data loss. Needs a mechanism to figure out the most recent write.
- Highest replica ID wins - ditto
- App-level conflict handlers, either at write or read time
- CRDTs / OTs
- Not sure I buy the “data loss” argument here; how is this different from single-leader, where a slightly later write overwrites a slightly earlier write?
- I think the difference is that in a single-leader system with linearizable writes enabled, the second write’s transaction won’t commit if it has read data modified by the first.
- Conflicts are typically resolved at the row level, not the transaction level
- Topologies
-
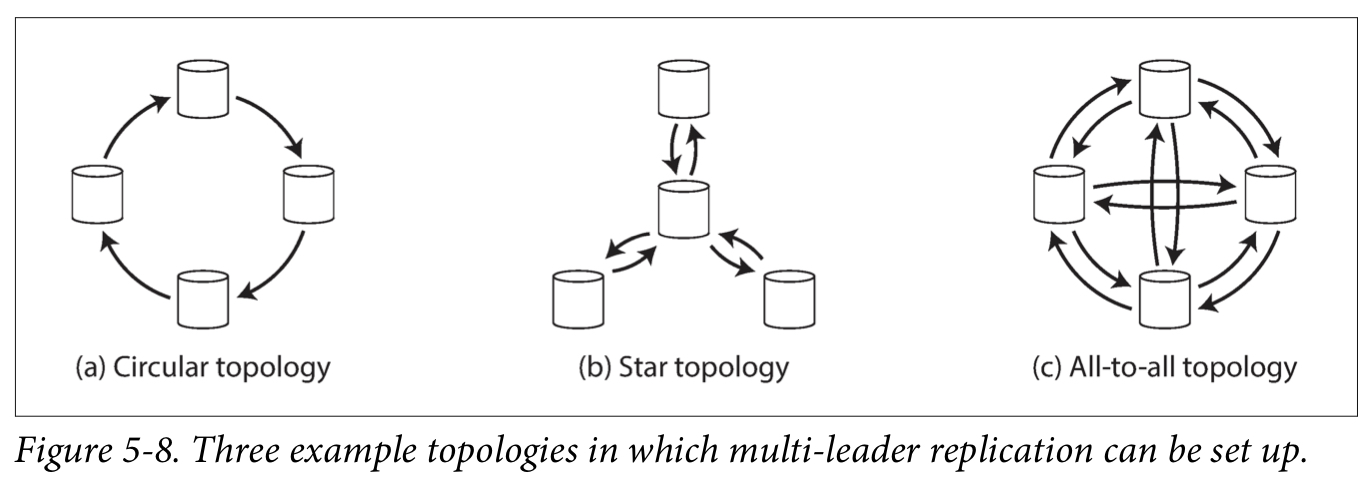
- Some topologies optimize for reliability, others for network congestion
-
- Leaderless
- Push the onus of replication onto the client
- These are called Dynamo-style databases (but DynamoDB isn’t one)
- Writes and reads are sent to all nodes. A quorum response is required for success in either case.
- Nodes that were down can catch up in two ways:
- Clients detect stale responses and write the newer value to the out of date node. This is called Read Repair.
- Some datastores have a background process that constantly looks for differences in the data between replicas and copies any missing data from one replica to another. Unlike the replication log in leader-based replication, this anti-entropy process does not copy writes in any particular order, and there may be a significant delay before data is copied.
- The quorum needn’t be sized symmetrically. For n nodes, pick r and w values such that $r + w > n$. Reads require r responses and writes require w responses.
- Concurrent writes don’t have an easy solution except merging them in some way (data loss)
- Many other timing issues like this. Also a node going down will break the quorum condition for some data.
- Version vectors can be used to provide causal ordering (in some cases?)
- Examples: Cassandra, Voldemort, Riak
- Only-leader
- These are databases (that I don’t think fit in any of the ^^^ categories) that accept reads and writes on all nodes using a consensus protocol for consistency.
- This makes reasoning about the system a lot easier, but performance must suck!
- Examples: CockroachDB
Ch6: Partitioning
- Shared-nothing == horizontal scaling
- Partition evenly/fairly to prevent hot spots
- Partitioning strategies
- Key-range (easy range queries)
- Key hash (better at avoiding skew / hot spots)
- Hash mod
: bad because a lot of data has to be moved if the node count changes
- Cassandra combines these two strategies for compound primary keys, which is a
(hash_key, range_key)tuple. - Current (as of writing) db systems can’t automatically handle hot spots with hashed keys, such as when a Twitter celebrity posts a tweet.
- Partitioning makes secondary indexes tricky; the common approach is to create a mapping from given filter value to primary keys that contain that value. Two approaches:
- By document: Each partition contains a secondary index for keys on that partition. Readers send queries (scatter/gather) to all partitions and combine them. Sensitive to latencies at higher percentiles.
- By term: Create a global index that maps filter values to all keys regardless of partition. This index needs to be replicated or even partitioned, but this can be done independently. Reads only need to go to partitions that contain the keys that need to be fetched, but writes require a distributed transaction (or are inconsistent for some time, like DynamoDB).
- Rebalance strategies
- Fixed partition count: create a lot more partitions than there are nodes. A new node steals some partitions from the existing cluster, and only data for those partitions need to be copied over. Generally requires that the partition count is specified at db creation time.
- Dynamic partition: automatically split (similar to a B-tree) a partition when it gets full. Useful with key-range partitioning; the key-range itself is simply split into two. Partition count grows with the data volume. Max number of nodes == partition count.
- Fixed partition count per node: when a node is added, it steals partitions from other nodes by splitting them. Can produce unfair splits.
- Fully automated rebalances can be tricky for the same reasons that automated failover is tricky.
- How do you handle routing requests to the right node for a given partition (or even find the right partition if the boundaries change dynamically)?
- Approaches
- Consensus using an external coordination service like ZK
- Use a gossip protocol to exchange this info between nodes (Cassandra)
- Consistent hashing
- Can either map from key->node or key->shard->node using a mixture of strategies
- For example, use consistent hashing to map from key->shardid, and then something like ZK to find nodes holding that shard
- Approaches
Ch7: Transactions
- Isolation/Serializability
- Read Committed: no dirty reads, no dirty writes (default in pg & others). Implemented with row locks for writers, and basic MVCC (old/new) for readers. Problems: read skew - if a second transaction changes (& commits) a value during your transaction, you might read two different values
- Snapshot: all reads look like they were done at the beginning of the transaction. Readers don’t block writers, writers don’t block readers. Implemented with row locks for writers, and full MVCC for readers. MVCC is implemented by tagging each write with a monotonic transaction ID, and having updates actually be appends. Readers are only allowed to read data with a txid <= their own. Problems:
- lost updates - if two transactions read & then update the same value, one transaction is not going to see the other update and clobber it.
- write skew - a more general “lost update”, where two transactions read the same objects, and update some of those objects, which could also lead to clobbering.
- Serializable: Strongest isolation level. Implemented by actually running transactions serially, using two-phase locking, or “Serializable Snapshot Isolation” (SSI).
- Two-phase locking: writers need an exclusive lock that lasts until the end of their transaction, and so block all other readers and writers for that time.
- Serializable Snapshot (SSI): Same guarantees as the Serializable level, but much more performant. Optimistic version of ^^^, which is generally pessimistic. Default in pg if you set
SERIALIZABLE. This is effectively snapshot isolation with a check for serializability violations at commit time; failing transactions are aborted/retried.
Ch8: The Trouble with Distributed Systems
- Network faults aren’t limited to the {available,unavailable} binary choice. For example:
- You could have network hardware that accepts incoming data but refuses to send outgoing data (or vice versa)
- Or have transient delays when a network switch update causes a topology rebalance.
- Timeouts are the only real way to detect whether or not a node is dead. You might be able to use diagnostic data from the network switches in your datacenter if you have access, but that’s not terribly reliable either.
- Long timeouts mean users see errors for that interval after the leader goes down
- Short timeouts mean you could potentially declare a working node dead - split brain, etc
- The right choice depends entirely on your workload and datacenter, and whether you have noisy neighbors or not.
- The choice needs to be made experimentally. Record a distribution of response times when the node isn’t down, and use that to guide the choice of timeout.
Most systems we work with have unbounded delays - there is no upper limit on the time it may take for a packet to arrive
-
If you’re using TCP, doesn’t the MSL (max. segment lifetime) value provide an upper limit? Actually maybe not; from RFC 1185:
the IP mechanism for MSL enforcement is loosely defined and even more loosely implemented in the Internet. Therefore, it is unwise to depend upon active enforcement of MSL for TCP connections.
-
Where can packets be dropped?
- Network switches buffer incoming data if it arrives faster than it’s own output rate. Packets are dropped if the buffer is full.
- The kernel buffers incoming data until a CPU is free to handle it. Data is dropped when these buffers fill up.
- VM coordinators buffer data for a particular VM if it isn’t currently running (scheduler); data is dropped if this buffer is full.
-
Phone calls use circuit-switched networks. A route + bandwidth along it is reserved when the call is established, guaranteeing a max. E2E latency. The internet is packet-switched instead, which is a better fit for bursty traffic patterns (no unnecessary/wasteful reservations), but causes all the issues we see today - queueing, dropped packets, etc.
-
Clocks: time-of-day vs. monotonic
-
time-of-day clocks typically use NTP, and can jump backwards or forwards if they drift too far off the mark.
-
NTP synchronization is only as good as the network delay.
- Great point that I hadn’t considered.
-
Some hardware might provide a separate monotonic clock per core, so comparing clock measurements captured across cores might be iffy, even if the manufacturer guarantees consistency.
-
It’s essential to monitor the clock drift for all machines that depend on it. Too easy for drift to go unnoticed.
-
Clock synchronization is a problem with LWW conflict resolution. Can Lamport clocks help here?
-
Think of clock measurements as confidence intervals instead of absolute measurements, like 95% confidence that the current time is between 100 and 200 ms after 13:05:00.
- The book mentions TrueTime, which always reports clock measurements as an
(earliest, latest)tuple.
- The book mentions TrueTime, which always reports clock measurements as an
-
Snapshot isolation requires a monotonically increasing transaction ID, which can be tricky in a distributed db that accepts writes at multiple nodes.
-
PaperSpanner gets a truetime measurement and uses
latestas the txid, but waits thelatest-earliestinterval before committing, which guarantees the transaction timestamp is at least latest. This allows for strongly consistent reads at any node without needing to contact the leader.
-
-
A single node can’t make any assumptions about the health of another node (even itself, because of GC and other pauses), so we use quorums instead. If a quorum decides a node is dead, that node is considered dead (even if it isn’t).
-
Fencing tokens are a monotonically increasing ID for leases/locks. If a node is granted a lease, but is immediately suspended until the lease is expired, it’s attempt to use the lease will then fail because the target will know both that the lease has expired, and whether or not another node has been granted a lease after expiry.
Ch9: Consistency and Consensus
- Linearizability / Strong Consistency
-
In short, all db access should look as though there’s only a single copy of the data. It’s ok to say “can’t service your request” to preserve the illusion, but you can’t break the illusion by producing old data/etc.
-
Reads before a write see the old value, reads after a write see the new value. Crucially, reads concurrent with a write can see the old or new value, but once a single client has seen the new value, no client should be able to see the old value anymore.
-
Snapshot isolation/SSI is not strictly linearizable because reads happen from a consistent (but potentially outdated) snapshot, so you aren’t guaranteed to be reading the most recent write.
-
Linearizability + serializability == strict serializability (also called one-copy serializability or 1SR)
- Transactions form a total order that respects real-time ordering (a transaction that ends before another starts appears first in the order)
- From http://www.bailis.org/blog/linearizability-versus-serializability/:
say I begin and commit transaction T1, which writes to item x, and you later begin and commit transaction T2, which reads from x. A database providing strict serializability for these transactions will place T1 before T2 in the serial ordering, and T2 will read T1’s write. A database providing serializability (but not strict serializability) could order T2 before T1.
-
Single-leader replication is potentially linearizable, multi-leader is definitely not.
-
RAM is not linearizable without fences/barriers (volatile?)
-
- Where is linearizability essential?
- Distributed locks, leader election
- Db constraints in a distributed env, like maintaining a UNIQUE index
- CAP Theorem
- Choose between CP and AP
- Simplistic because:
- The CAP system model is a single, read-write register – that’s all. Nothing to do with transactions.
- There are more failure modes to consider than just network partitions. Crashes, reboots, running out of disk space, etc.
- Nothing about latency
Linearizability is always slow, even when there isn’t a network partition.
Ordering
The idea of ordering is inextricably linked to the idea of linearizability (and consistency):
The difference between a total order and a partial order is reflected in different database consistency models:
Linearizability
In a linearizable system, we have a total order of operations: if the system behaves as if there is only a single copy of the data, and every operation is atomic, this means that for any two operations we can always say which one happened first.
Causality
We said that two operations are concurrent if neither happened before the other. Put another way, two events are ordered if they are causally related (one happened before the other), but they are incomparable if they are concurrent. This means that causality defines a partial order, not a total order: some operations are ordered with respect to each other, but some are incomparable.
Therefore, according to this definition, there are no concurrent operations in a linearizable datastore: there must be a single timeline along which all operations are totally ordered.
- This also implies than linearizability implies causality because it is a stronger guarantee.
- Causal consistency is sufficient for many use cases, and can remain available in the face of network failures.
Concretely, ordering means that all reads and writes are ordered in some way, either in a causal or total order.
In a linearizable system, if you want to read a value from a node, that read operation needs a place in the total order, which implies that the read will wait until the node is fully caught up.
It sounds like a causally consistent system is simply an eventually consistent system where causal order is preserved. If the same row is modified twice, the update is applied in the same order on all replicas. This is pretty much what I would expect eventual consistency to be in a single-master system, but apparently eventual consistency doesn’t guarantee any sort of ordering, only that all nodes will eventually converge on the same (not necessarily causally last) value.
Is this a purely academic distinction? I’d be surprised if any single-master production replication systems didn’t provide causal consistency. Sounds like yes:
In a database with single-leader replication, the replication log defines a total order of write operations that is consistent with causality. The leader can simply increment a counter for each operation, and thus assign a monotonically increasing sequence number to each operation in the replication log. If a follower applies the writes in the order they appear in the replication log, the state of the follower is always causally consistent (even if it is lagging behind the leader).
Causal consistency can be maintained be defining a total order across the system. The replication example above cheats a bit because all writes happen on a single machine, so the total order is built by CPU execution order on that machine. Lamport timestamps provide a generic mechanism to accomplish this that scales beyond a single machine:
- Tuple of
(monotonic counter, node ID). Timestamp with the larger counter is the greater timestamp, node ID breaks ties. - Every client keeps track of the current timestamp and includes it (each time with an incremented counter) with every request.
- Every node keeps track of the largest counter it has seen so far, and sends it back (incremented) to every client; each client then updates its local counter to this value if it’s greater.
- This is sufficient to create a total order; every operation against a given node has a unique lamport timestamp.
- Note that “node ID breaks ties” might introduce causal inconsistencies, though.
The total order only becomes apparent in hindsight, though. For example, a conflict in a UNIQUE constraint can be resolved by picking the earlier timestamp, but a given node can’t make this decision in (faux-)realtime. It needs to communicate with all other nodes (implying CP) to figure out who holds the earlier timestamp.
Total Order Broadcast is the solution to finalizing a total order. It is a protocol for exchanging messages between nodes, and requires that these two properties are always satisfied: messages are always (eventually) reliably delivered to all nodes, and all messages are delivered to every node in the same order.
This effectively describes an immutable log of messages. The order can’t be changed once finalized, only appended to. With this model you can create a linearizable CAS operation that can be used to implement the UNIQUE check from above:
- Write a message to the log tentatively claiming the username
- Read the log looking for your message
- The first message that claims the username wins
Two ways to implement linearizable reads:
- Add an “I want to read” message to the log, wait for it to be delivered to you, and perform the read at that point in the log. (etcd does this)
- Fetch the latest log offset in a linearizable way, wait until you’ve read up to that point in the log, then perform the read. (zk does this with
sync())
Actually implementing this requires consensus.
Consensus
-
Two-phase commit is used for distributed transactions, but can be generalized to a (bad) consensus algorithm.
- A coordinator starts single-node transactions on each participating node
- When ready to commit, the coordinator sends a “prepare” request to each node. Each node responds “yes” if it is ready to commit, but must also be sure that it can commit no matter what. It surrenders the right to abort the transaction (which implies writing the current state to a WAL, making sure disk space exists, etc.)
- If the coordinator doesn’t receive a “yes” from all participating nodes, it asks all nodes to “abort”; if not it asks all nodes to commit. Either way it writes its decision to disk. If a node doesn’t acknowledge or is down, the coordinator must retry this request forever until it receives an ack.
- If a coordinator fails after a node has responded to a “prepare” request, nothing can happen until the coordinator comes back up - at that point the coordinator can check disk to see if it already made a decision and broadcast that. If no decision was written yet then it sends an “abort”.
-
If a distributed transaction is stuck, all the locks held can’t be released. Depending on the isolation level this could end up being severe.
-
MySQL distributed transactions are 10x slower than regular transactions!
-
2PC across different technologies can be powerful (read from a message queue + commit to db in a single transaction) but finicky; Open XA is a standard for this.
A formal representation of the consensus problem is: one or more nodes propose values, and the cluster decides on one of the values. In general these properties must be satisfied:
- No two nodes can decide on a different final value
- No node can make this decision more than once
- The final value chosen must have been a value that was proposed
- Every node that hasn’t crashed will eventually decide on a value
This final property sets consensus apart from 2PC, which can end up sitting around doing nothing forever if the coordinator crashes. Main caveat is that a consensus algorithm typically requires at least
Examples of consensus algorithms:
- Viewstamped Replication
- Paxos
- Raft (etcd)
- Zab (Zookeeper)
These algorithms are modeled against total order broadcast, where they build consensus around a shared log; each append to this log requires a quorum to agree.
Single-leader replication creates a total order as well, but isn’t really consensus because the choice of leader is done by a human, so the fourth property isn’t satisfied.
It seems that in order to elect a leader, we first need a leader. In order to solve consensus, we must first solve consensus. How do we break out of this conundrum?
To break this catch-22, consensus algorithms divide time up into epochs and only guarantee that a single unique leader exists within each epoch. When a leader is unreachable, a new epoch starts and a new leader is elected. Every decision that leader makes is also voted on. The epoch number is sent with every request and every node checks that a newer epoch hasn’t started before voting.
Because quorums require majorities, a successful vote on a proposal implies that a new epoch hasn’t started. At least one node that voted on the proposal was definitely a part of the vote during the most recent leader election.
Flaky networks can make consensus algorithms behave erratically (but not incorrectly), with leaders bouncing around, etc.