6.824 Lecture 4 - Primary-Backup Replication
- Lecture: https://www.youtube.com/watch?v=M_teob23ZzY
- FAQ: https://pdos.csail.mit.edu/6.824/papers/vm-ft-faq.txt
- PaperPaper Notes
- Stopped at 53:46
-
Fail-stop faults
- The kind of fault where the computer halts completely (from the PoV of the outside world)
- As opposed to continuing to run + producing invalid outputs
- Doesn’t necessarily cover hardware defects, programming bugs
- You can convert non-fail-stop faults to fail-stop faults by shutting yourself down when you see:
- An invalid TCP checksum
- A corrupted disk block
- etc.
-
Replication doesn’t help when correlated faults occur
- I wonder how well this plays with the requirement for extremely similar performance from the backup
-
Replication isn’t always worth the duplication in resources; this is an economic decision.
-
Two approaches to replication:
- State transfer: replicate the state of CPU/memory/etc. directly
- Replicated state machine: start with identical state, and only replicate inputs + non-determinism
-
VMWare has since come up with a new system that works with multi-core VMs, and this one uses state transfer.
-
Not feasible to perform a failover without any clients noticing; need a way to get clients to switch over.
-
Creating a new replica VM during failover requires a full state transfer, so this is expensive
-
It’s rare for replication to be as comprehensive/low-level as this system (I’ll say!) Almost all systems use application-level replication, which (naturally) requires applications to be aware of the replication.
-
Typical VM:
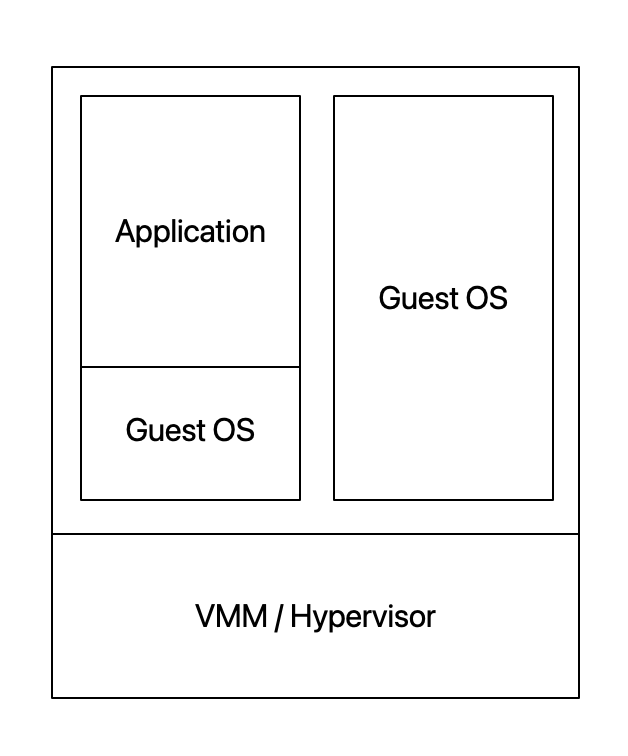
-
VMWare FT network replay:
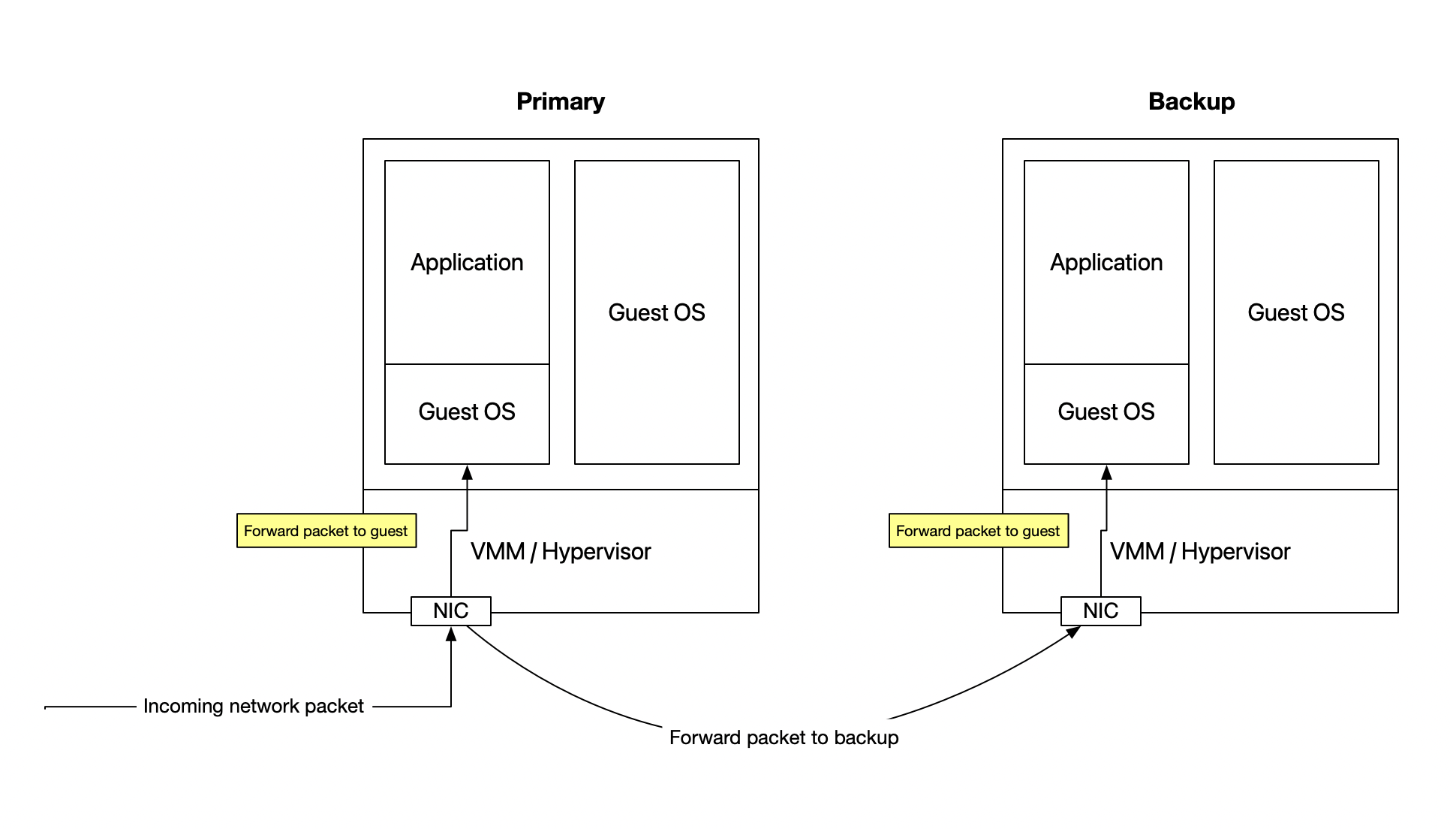
-
Each timer interrupt generates a log entry; these occur 100s of times a second.
-
The paper hints that they got Intel to add support to the hardware to make it easier to manage non-determinism here
-
Sources of non-determinism
- Interrupts generated by incoming network packets (must occur at the same CPU instruction on both VMs)
- Non-deterministic instructions (time, RNG, etc.)
- More than one core
-
Contents of a log entry
- Instruction number/offset (for entries that don’t directly correspond to a CPU instruction - like an interrupt - this is set to the last instruction the CPU has executed at that point)
- Type (interrupt/instruction/etc.)
- Metadata incl. mitigations against non-determinism
-
The backup’s VMM isn’t forwarding hardware interrupts to the guest, but only the interrupts from the logging channel
-
The VMM arranges with the CPU (there’s an instruction for this) to interrupt at well-known intervals, so it can line up the instruction numbers
- Is this right? Why do we care about instruction numbers for the hardware CPU? I’d assume that we could get away with aligning the instruction numbers of just the virtual CPUs
- This would imply that the VMM is pinned to the same hardware core for the duration of the execution, which sounds like an unnecessary constraint as well
-
Vast majority of log data is going to be network traffic in a typical server scenario. Ditto for output.
-
Can’t expect clients to do any extra work to detect faults (like in
PaperThe Google File System) because this is intended to run unmodified software, which extends to clients of that software as well -
The Output Rule has an analog in pretty much every replication system that needs to maintain consistency
-
Pretty much impossible to guarantee exactly-once delivery for output during a cutover (in any replication system).
- The backup needs to assume that the primary’s output was lost, because it very well could have been.
- This implies that clients need to build in a deduplication scheme; this system uses TCP
-
Failover must wait until the shared storage server sends back a response to the CAS. Failover can’t proceed if it’s down, so it’s probably a FT system as well.
-
Q: How were the creators certain that they captured all possible forms of non-determinism?
A: My guess is as follows. The authors work at a company where many people understand VM hypervisors, microprocessors, and internals of guest OSes well, and will be aware of many of the pitfalls. For VM-FT specifically, the authors leverage the log and replay support from a previous a project (deterministic replay), which must have already dealt with sources of non-determinism. I assume the designers of deterministic replay did extensive testing and gained experience with sources of non-determinism that the authors of VM-FT use.