The Design of a Practical System for Fault-Tolerant Virtual Machines
- https://pdos.csail.mit.edu/6.824/papers/vm-ft.pdf
- Published in December 2010
- This was a fun paper to read; the idea of replicating entire VMs is so audacious I never imagined something like this could actually exist!
- I largely skipped the Performance section
1. Introduction
-
Fault-tolerant VMs by replicating the execution of one VM onto a backup VM
-
Included in VMWare vSphere 4, works on commodity hardware. Officially called VMWare FT.
-
It’s possible to perform this kind of replication by replicating all state exactly, incl. CPU, memory, and IO, but this would require far too much bandwidth (state transfer)
-
Another approach is to start both servers from a known (identical) state, and then making sure that the secondary recieves the same external input as the primary (replicated state machine)
-
If the inputs are guaranteed to be identical, is there no way for the VMs to drift?
- I was thinking of non-deterministic behavior like generating random numbers, but these aren’t really non-deterministic.
- The clock is another one, but the VM controls this fully, so it’s possible for the backup to see the same external inputs at exactly the same wall-clock times as the primary
- Speculative execution is somewhat non-deterministic, but I’d imagine that this is entirely a function of what you’re running, what’s in the caches, etc, which should all line up here. ==Does FT support speculative execution?=
- What about the VMs themselves making external requests, though?
- What if an app generates random numbers seeded by current timestamp, and both VMs make NTP requests that receive different responses?
-
Low bandwidth requirements (~20Mbps) make it possible to run this sort of replication in a somewhat geographically distributed way
-
Sounds like this is intended to work without any application support:
Since VMware vSphere implements a complete x86 virtual machine, we are automatically able to provide fault tolerance for any x86 operating systems and applications.
-
Only single processor (not even multiple cores) VMs are supported at the time of writing
Recording and replaying the execution of a multi-processor VM is still work in progress, with significant performance issues because nearly every access to shared memory can be a non-deterministic operation
- The interaction of more than one processor is non-deterministic
- Even for something simple like acquiring a lock - subtle timing differences might cause different results on the two VMs
- It’s possible to guarantee a stable ordering for a single set of instructions
- It’s impossible to guarantee a stable ordering for more than one set of instructions, because you can’t even predict all the ways those sets of instructions may affect each other, much less line them up
-
The system only attempts to guard against fail-stop failures (as opposed to crash-stop?)
2. Design
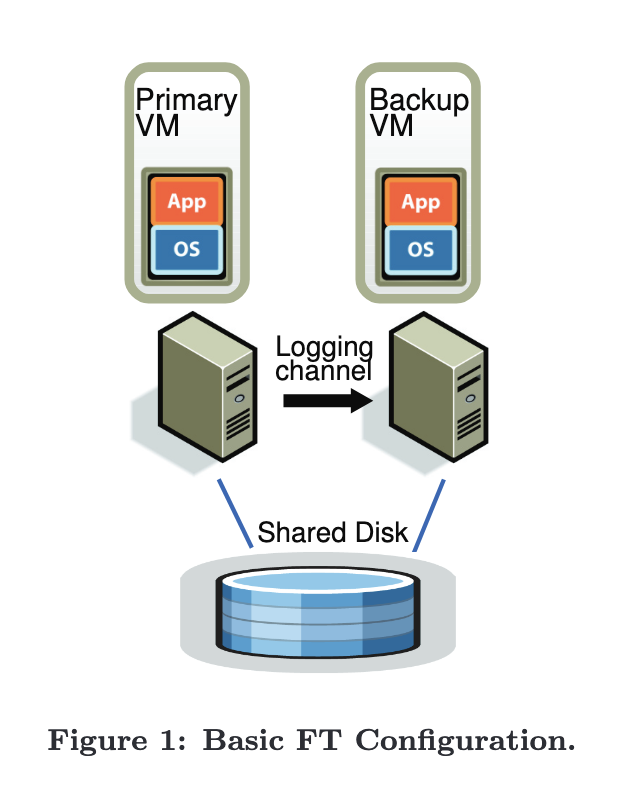
-
Each VM is on a different physical server, but they share a disk (SAN)
-
The primary receives all user/external input, and sends this on to the backup via the logging channel
-
The hypervisor drops all the “outputs” of the backup VM, but its execution is otherwise identical to the primary
-
Three challenges
- Capturing all input and non-determinism required for deterministic replication
- Applying the inputs correctly
- Many x86 operations have undefined/non-deterministic side effects
-
VMWare’s deterministic replay does essentially this; it captures all inputs to the primary + all non-determinism, and replays this to the secondary via a stream of log entries
-
Examples of non-determinism: timer/IO interrupts, reading a time-of-day clock
-
Interrupts are handled by recording the exact instruction at which they occur. Other forms of non-determinism presumably each need special handling like this.
-
Output Requirement: if the backup VM ever takes over after a failure of the primary, the backup VM will continue executing in a way that is entirely consistent with all outputs that the primary VM has sent to the outside world
- Achieved by delaying primary output until the secondary has replayed upto the point of that very output
- If the secondary hasn’t caught up to that point, a failover might cause it to take a different path prior to that output, which is inconsistent
-
Output Rule: the primary VM may not send an output to the external world, until the backup VM has received and acknowledged the log entry associated with the operation producing the output.
- Network packets are a form of output
-
The primary doesn’t need to entirely halt in advance of an output while waiting for the secondary to catch up; the output needs to be delayed, but the VM can continue executing.
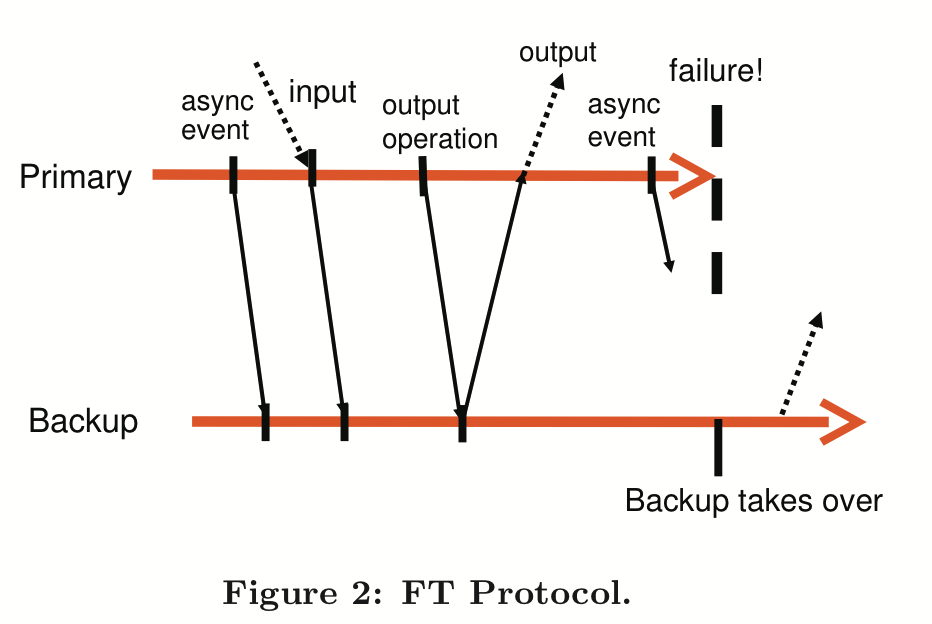
-
The system cannot guarantee that outputs aren’t duplicated when a failover occurs. There’s no way to tell whether the primary crashed before or after performing the output, so the secondary must replay the output.
-
Some inputs could be dropped in the event of failover, but it sounds like the system just relies on TCP retransmission (or the equivalent) to overcome this
-
When a failover occurs, the backup must first drain the queue of logs, execute all of them, and only then begin “normal” execution. Output is also unblocked during the switchover.
-
The backup has a different MAC address, and this needs to be broadcast
-
UDP heartbeats, but the log stream serves as a heartbeat too. Timer interrupts ensure a steady log stream even on an idle system, so a steep drop in log volume could signal that the primary is down.
-
Shared storage is used to avoid a split-brain situation here. When the primary detects that the backup is down or vice versa, it executes an atomic CAS on the stared storage.
- If this succeeds, the VM is allowed to continue executing as normal, without a backup (the paper calls this going live).
- If this fails, the other VM must have gone live, so this VM must halt/shutdown
-
The VM must simply wait for the shared storage to be available if it is down. Virtual disks are stored on this layer as well, so shared storage being down probably means the VMs can’t do much anyway.
-
When a go live event occurs, a new backup VM is created on a new host.
- How does this backup VM catch up to exactly the primary VM’s state?
3. Implementation
- VMWare already has something called VMotion that allows migrating a running VM from one server to another with a <1s pause
- VMotion can be adapted to clone a VM instead of migrating it, set up a logging channel, and mark the source VM as the primary and the destination as a secondary
- All this can be done in under a second as well
- Is this <1s because shared storage enables a copy-on-write mechanism, or are disks copied over in advance of the actual switch (and if so how does the backup catch up to now?)
- The paper doesn’t go into design/implementation details for VMotion
- Hypervisors on both sides buffer log messages
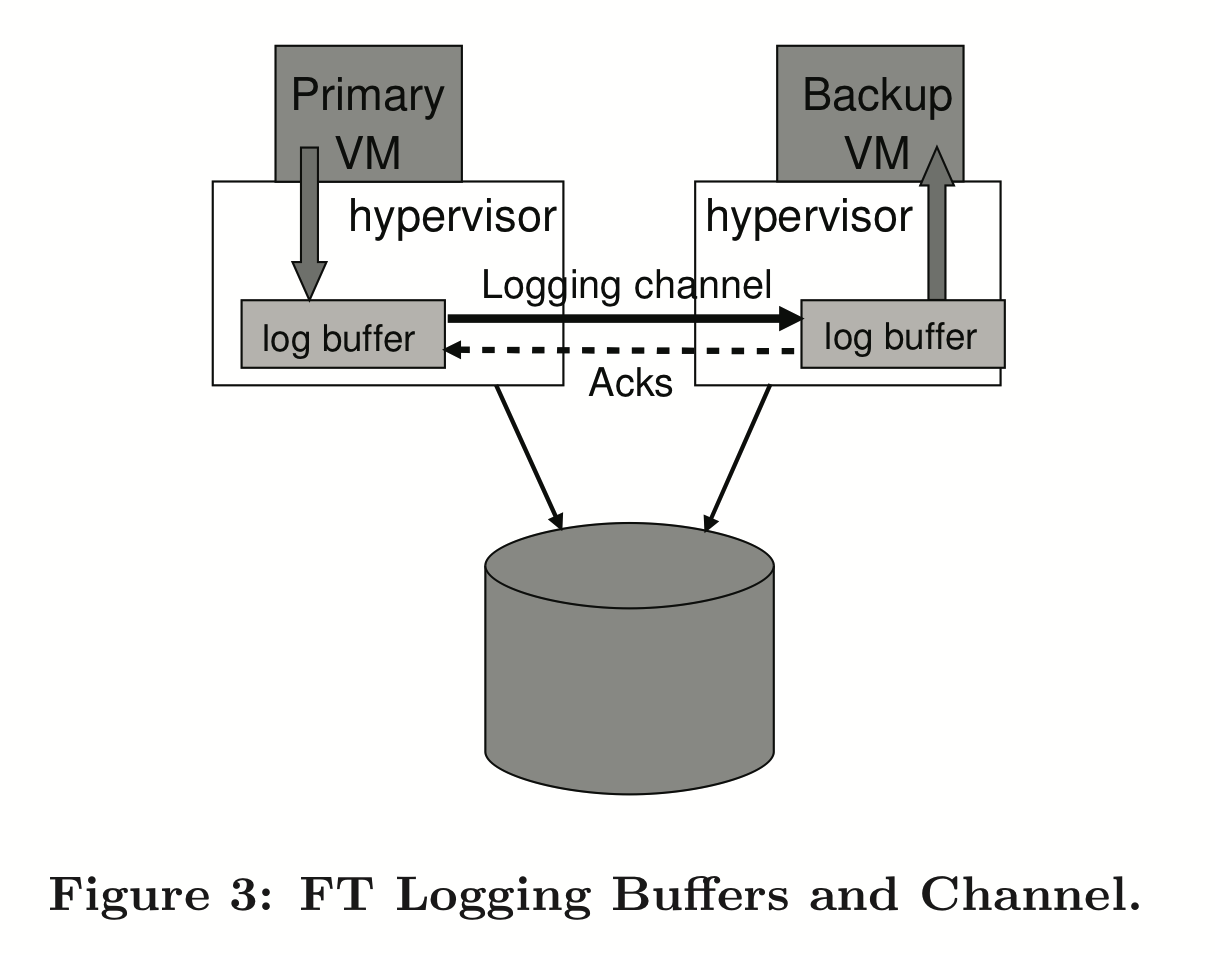
- The backup sends an ack every time it reads from the network into its buffer
- These acks allow the primary to unblock “output” that was waiting for the backup to catch up
- The primary pauses execution if its log buffer is full; no overflows!
- The backup must be able to execute log entries at the same speed as the primary (or faster) to make this scenario unlikely
- After a failover, the backup must wait until it executes all buffered messages, so that’s another reason to not let these buffers fill up
- What happens if the backup’s buffer is full but the primary’s isn’t? Does the primary keep resending until an ack?
- How is log ordering guaranteed?
- Conversely, the backup pauses if its buffer is empty
- There’s realtime measurement of latency/execution lag between the two VMs, and the primary is throttled if this lag starts to become large
- This might happen when the backup is running slower than the primary for some reason
- Generally rare for this to happen in practice
- Control operations (power off, change resource allocation, etc.)
- These should be done on the primary, and the system will replicate this change to the backup as well
- VMotion is the one exception (in this context, I think this means migrated, not cloned) independently
- When the primary is migrated, it needs to wait until all ongoing disk IO is done, and then perform the switchover
- When the backup is migrated, it asks the primary to wrap up disk IO, this completion is then replicated over, and the switchover happens at that point
- This presumably adds up to a second to the replication lag
- The VM that wasn’t migrated needs to disconnect from the old VM and reconnect to the new migrated VM
Disk IO
- Disk IO counts as “output”, so the backup effectively performs no disk IO
- Non-determinism
- Issues
- Disk operations can occur in parallel, so this can lead to non-determinism. There’s no way to ensure that two identical disk IO operations take the same amount of time at the hardware level
- VMWare uses DMA for disk IO (disk controllers read directly from main memory), so parallel operations that are reading off the same memory page can be non-deterministic as well
- CPU memory access to a page that is the target of disk IO can also cause non-determinism
- One solution is to disallow CPU access for pages that the disk is accessing.
- This would require pausing the VM, but setting up the traps necessary on the MMU is expensive as well.
- The system uses bounce buffers instead
- Allocate a buffer in the hypervisor’s memory space that’s the same size as a specific disk IO operation
- Disk reads populate this buffer, and it’s only copied to (possibly under-contention) guest memory when the IO has completed (at which point non-determinism has ended)
- Disk writes write from this buffer as well
- This is a way to have the backup’s CPU execution happen in the same order as the primary in the face of variable/parallel disk IO
- Issues
- It’s possible for a disk IO op to be in progress when the primary crashes
- When the backup goes live, it re-issues all disk IO operations in the log that didn’t complete
- This duplicate IO is guaranteed to be idempotent, so this is at worst a slight performance issue
- What if one of these started a long time ago? Is the backup not allowed to delete an disk IO log entry until that operation completes?
Networking
- The hypervisor typically asynchronously updates the state of VM network devices via “DMA” into VM memory
- Example: TCP receive buffers can be updated directly when the VM is executing
- This adds non-determinism, and needs to be disabled for replicated VMs.
- Without this feature enabled, each incoming packet needs to trap to the hypervisor
- This kills performance, obviously; this is somewhat improved by:
- Batching: trap for groups of packets instead of every single one
- Use a single trap for incoming and outgoing batches that occur at the same time
- Allow registering functions to run in deferred-execution contexts when TCP data is received
- This allows network IO for logging and acks to occur without thread context switches
- What is a deferred-execution context?
Alternative Designs
- Non-shared disks
- The system as it stands uses a shared disk, so each disk IO operation is considered an “output” (and is bound by the Output Rule).
- An alternative is to have the primary and backup VMs use indepdent disks that are considered internal to their state.
- Writing to these disks wouldn’t count as outputs anymore. Presumably a perf win for disk-heavy workloads.
- The two disks need to be synced up before fault-tolerance can be enabled (also during a failover, I imagine)
- This makes it harder to break a split-brain situation. You’d need something like leader election or a (separate) shared disk just for this purpose
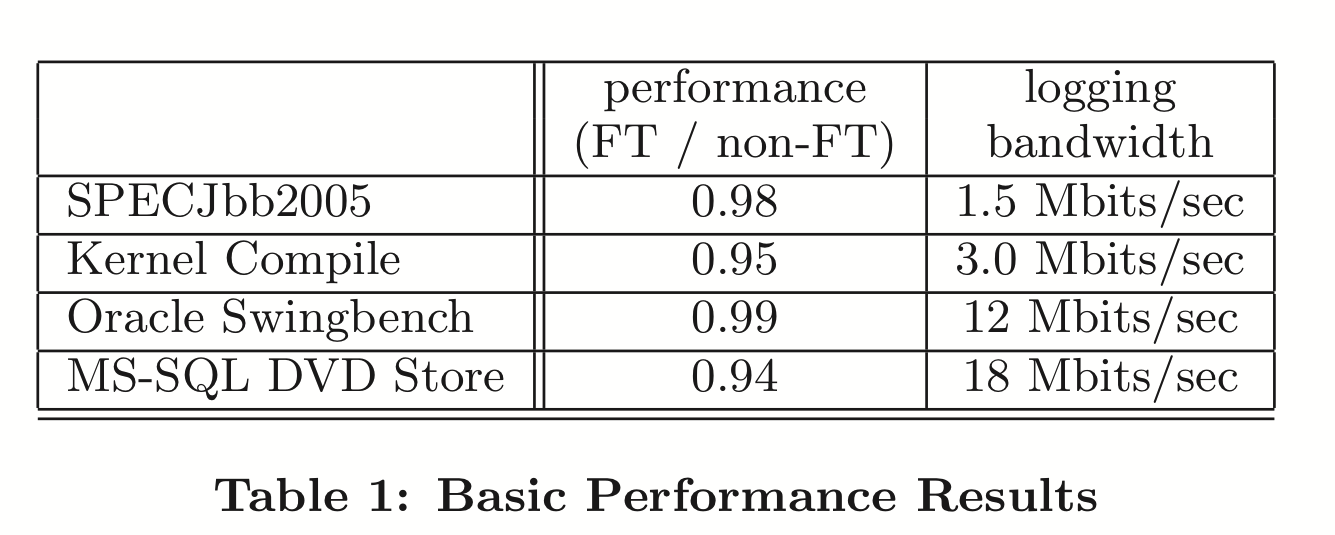
Performance