6.824 Lecture 1 - Introduction
- Why incur the costs of distributed systems?
- parallelism for performance
- fault tolerance
- physical reasons (bank transfer between two banks' infra)
- sandboxing / security
- Difficulties
- Failure modes are much more diverse / partial failures
- Performance doesn’t scale linearly
- Used to be an academic curiosity before the modern web made it more practical
- Paper per lecture, read before lectures
- Labs
- MapReduce
- Raft
- HA KV store using Raft impl.
- Shard the KV store
- Types of infra systems
- Storage
- Computation
- Comms
- Linear scalability is rarely infinite; bottlenecks can move
- Rare faults can become common when you have enough computers / instances
- Tools for fault tolerance
- Non-volatile storage (slow to update)
- Replication
- Consistency
- Strong consistency is very expensive
- Lots of interest in practically useful weak consistency schemes
- Replicas are only useful when they have uncorrelated failure probabilities (not in the same rack!)
MapReduce
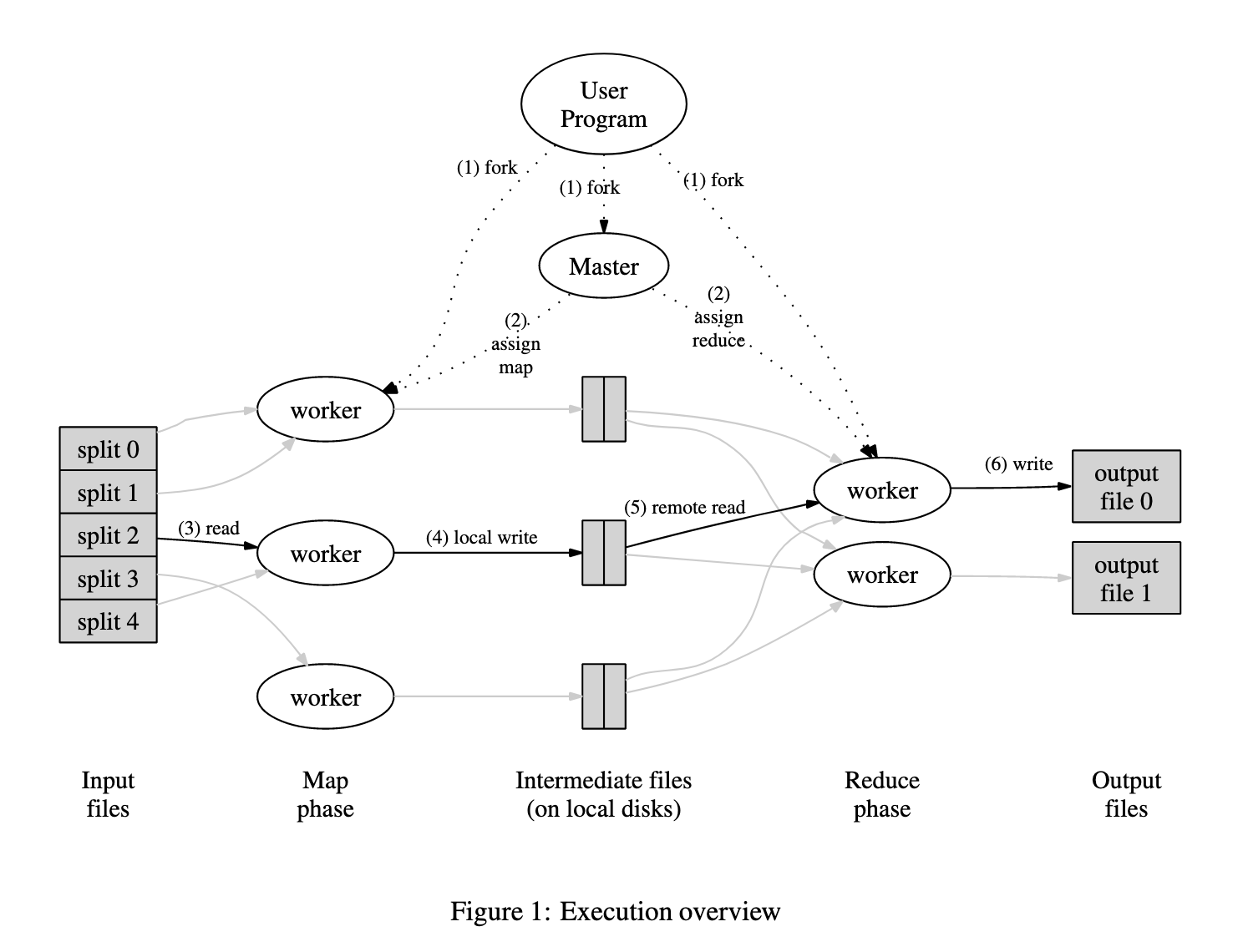
- PaperMapReduce
- Old way: write bespoke distributed systems for each type of distributed computation
- MapReduce is a framework/abstraction to be able to run run distributed computations without having to worry about the details of how the computation is distributed
- Write a map & reduce function that don’t know anything about distribution
- Input files, the map fn is executed on each one, and produces intermediate output as KVs
- Map functions have to be completely pure and independent of each other
- KVs for unique K (across all intermediate output) are sent to one call to reduce
- Map functions emit KVs; for a word count operation this is just (
<word>, 1)- If a single map operation sees multiple instances of a word, does it combine them, or are the emitted multiple times separately? Multiple times separately, but a combiner function can be specified to make things more efficient. See PaperMapReduce > Refinements
- If a single map operation sees multiple instances of a word, does it combine them, or are the emitted multiple times separately? Multiple times separately, but a combiner function can be specified to make things more efficient. See
- MapReduce jobs are routinely pipelined in serial; PageRank initially did something like this
- A shared distributed filesystem makes it easy for reduce jobs to read all intermediate output (the alternative would be to have each reduce function talk to every other worker asking for data).
- GFS splits up large files into 64MB chunks, so initial read throughput can be high; the master presumably hands workers map jobs that they can read entirely (or mostly) from local disk.
- Network was a major bottleneck “in the world of this paper”, and a lot of the design here tries to minimize file transfers over the network.
- Main example here is to have GFS running on the same machines as the MR workers.
- Modern systems might be more stream-oriented (don’t need to wait until all maps are done before reducing)
- Modern datacenters have more network throughput, making MR obsolete for Google at least