A Better Model for Stacked (GitHub) Pull Requests
Stacked pull requests are a useful tool to make large changes comprehensible, but managing these stacks can be tricky. This post introduces the idea of stacked PRs, and goes over strategies and tooling to make managing these stacks easy.
Code review using GitHub pull requests (PRs) is generally pretty decent, but you’re going to have trouble with medium-to-large changes, especially when the dependencies involved mean you can’t split them up into disparate PRs. Every change/feature typically goes in a single PR. Changes that build on the original either go in the same PR, or have to wait until the PR is merged so a second PR can be created.
When a single large PR has well-formed commits, it’s fairly easy to review it sequentially, but there are other potential problems. Commits can’t be approved individually, so you have to treat the entire PR as being in progress until it’s done, even if only a small part is in contention. Dependent-but-unrelated changes are problematic too. You have to put them in a single PR, which can be confusing all around.
The only real solution to this problem (that I know of, anyway) is the notion of stacked PRs. Here’s the basic idea:
- Create a pull request from a feature branch (say
feature-1) tomaster - Create a second pull request from another feature branch (say
feature-2) tofeature-1 - Repeat until you have a stack of pull requests
- When it’s time to merge, start from the topmost PR (the one that’s furthest from
master) and merge/rebase every PR in until you merge the entire stack in tomaster
GitHub (unfortunately) doesn’t provide any native support for stacked PRs, but (assuming you can’t switch to another tool), managing a stack of PRs isn’t too hard to do manually. There are a couple of nuances to keep in mind, as well as tooling that can help automate most of the annoying bits away. I’ll cover all of that in the rest of this post.
After having used the stacked PR workflow for a while, the benefits are readily apparent:
- Dependencies: Changes that your feature depends on (but are otherwise unrelated) can go in a separate PR.
- Reviewers: Every PR in the stack can potentially be assigned to a different set of reviewers, which can be helpful in a few different contexts - ramping, areas of expertise, or workload.
- Incremental approval: Large, thorny changes can be approved in pieces.
First, let’s go over a visual example of a stack of PRs. I find that git concepts are much more easily understood with a visualization than text!
The Stacked PR Workflow
Legend:
- Circles represent commits, with their SHAs inscribed.
- Arrows represent parentage - an arrow leads from a child commit to its parent.
HEADrefers to the commit that’s currently checked out.- A branch like
masterrefers to a local branch with that name. - A branch like
origin/masterrefers to amasterbranch on theoriginremote that we’re tracking locally
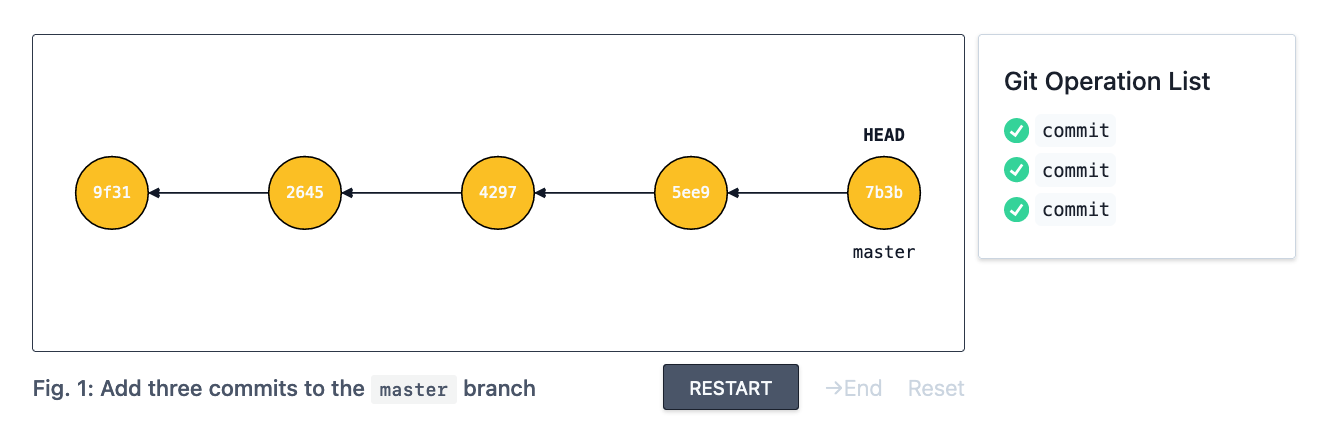
To start with, here’s a simple visualization that adds a few commits to the master branch. Note that you can hover/tap on entries in the Git Operation List section to skip ahead/behind.
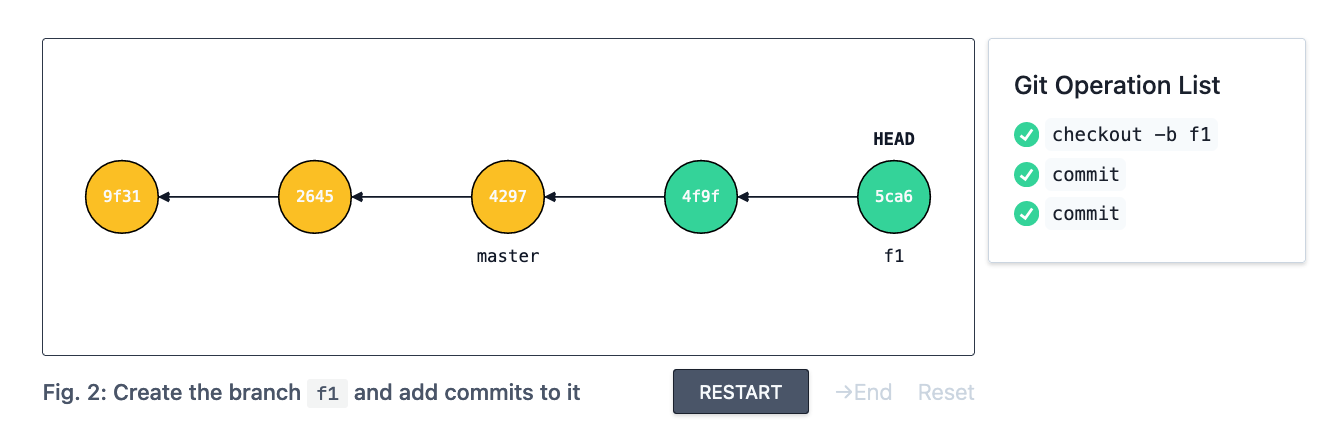
Now that we have some commits on master, let’s create a new feature branch named f1 and add a few commits to it.
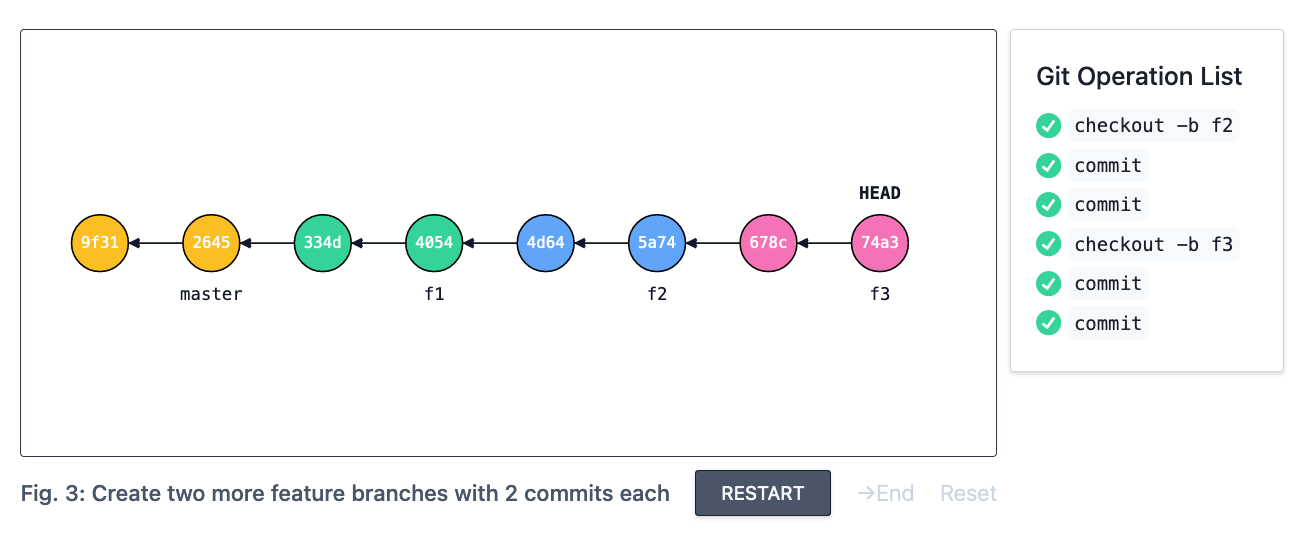
Repeat this process two more times to create a stack of feature branches.
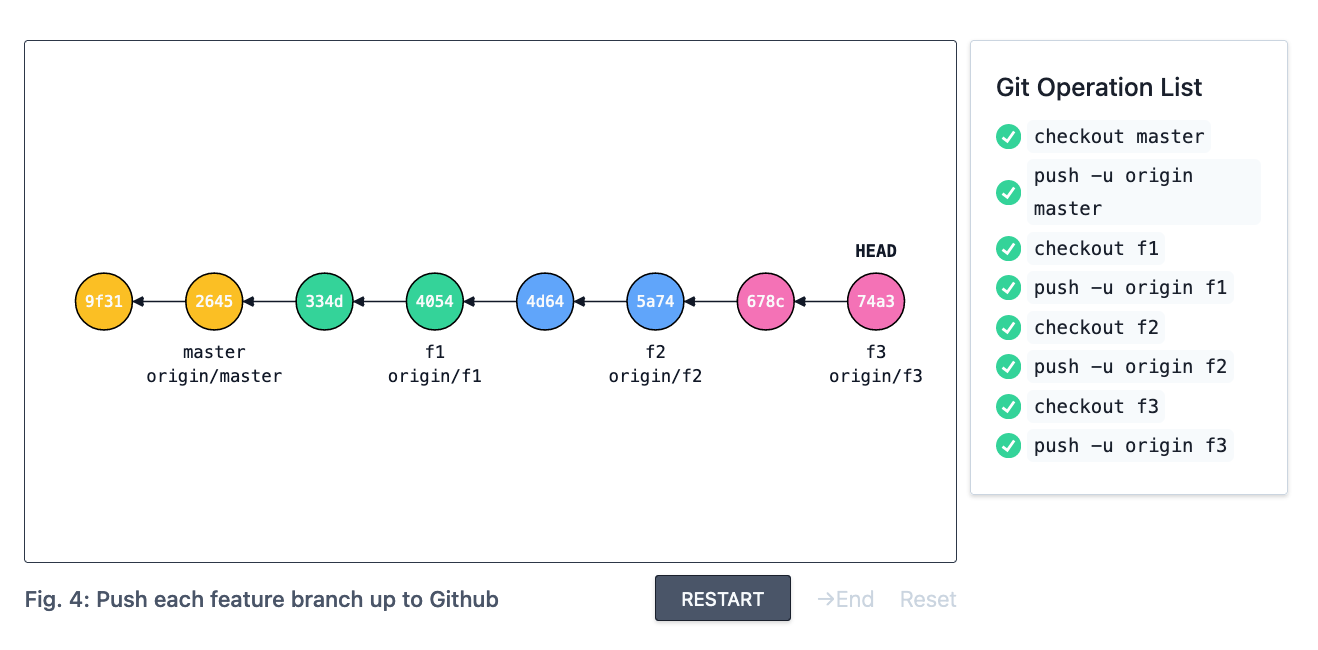
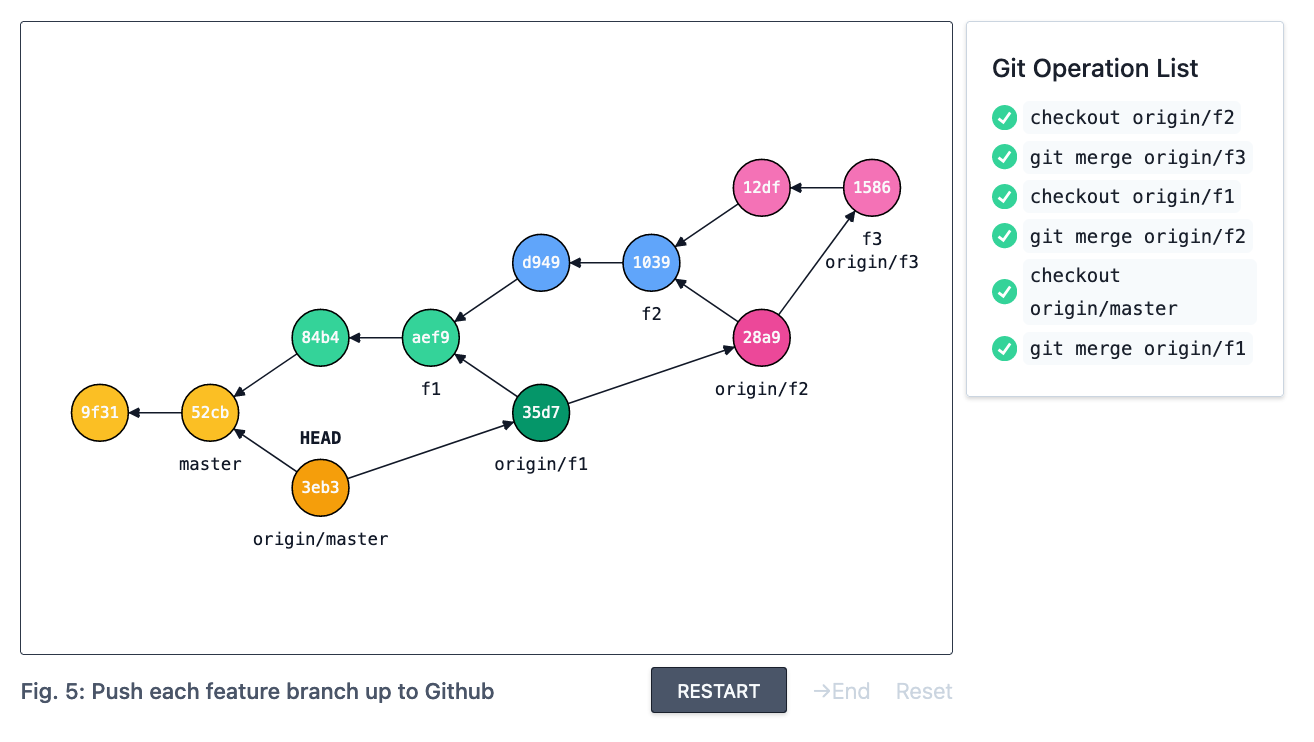
Finally, push each branch up to GitHub. This will add the origin/* (assuming your remote for GitHub is named origin) tracking branch against every local feature branch.
At this point you would use GitHub’s Pull Requests UI to create a PR for each branch. This will end up looking something like this (note the merges into target for each PR):



You now send these three PRs out for code review. If they’re approved with no changes requested, you’re good to go! Merge in the stack from top to bottom - in this case we’re going to merge Feature 3’s PR, Feature 2’s PR, and Feature 1’s PR, in that order, using GitHub’s UI.
GitHub’s master branch now points to a merge commit that comprises the sum of all changes in the PR stack – we’re done merging the stack!
If you find that all the merge commits here make the git history hard to read, you can use git merge --squash at the final merge to master instead, which will leave you with a single new commit on master.
Changes During Code Review
Of course, code reviews aren’t typically this frictionless in practice. Changes are requested, you go back and forth, and the feature branch in question sees active development during the life of the pull request.
Let’s assume that all three feature branches require a change each, resulting in one commit added to each feature branch:
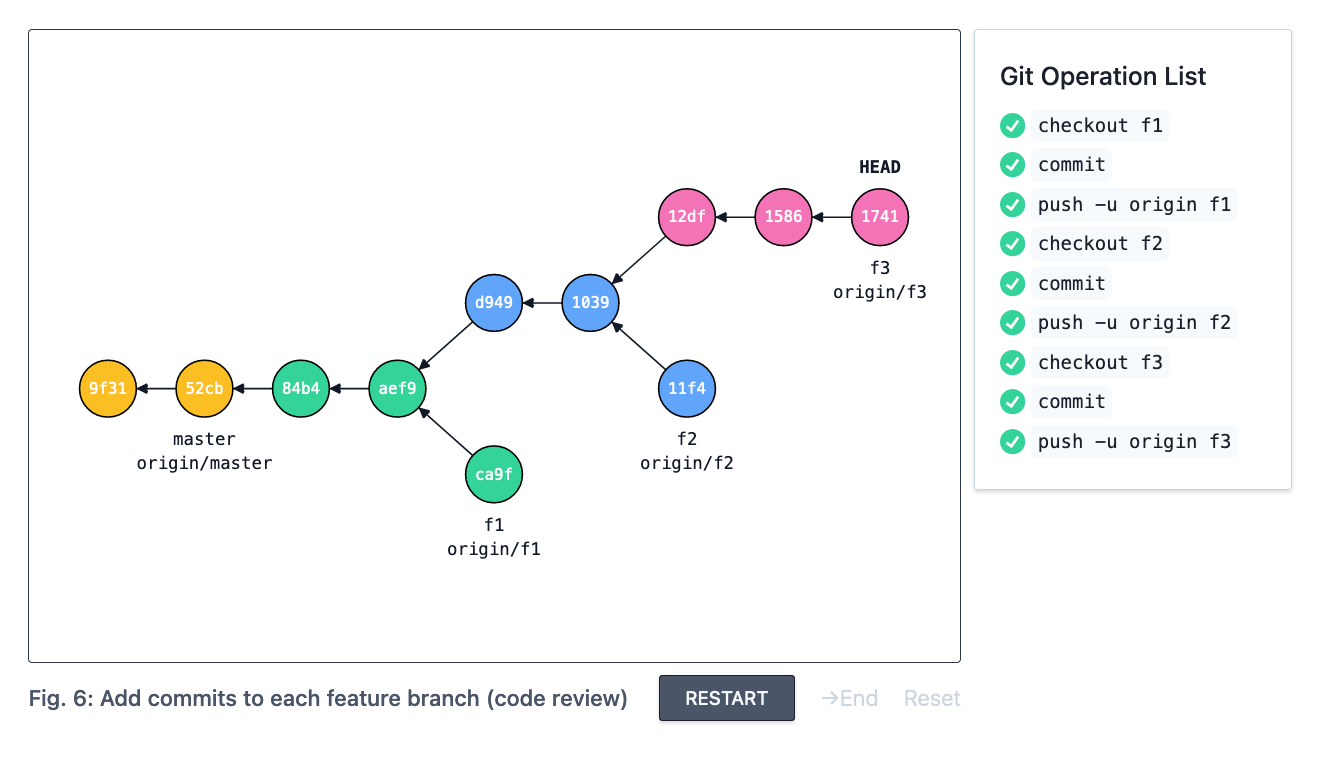
Now if you start from the commit that’s added to f3 and follow the ancestry chain all the way to master, you will miss the new commits added to f2 and f1. This could be a problem - these two commits might contain changes that f3 depends on, but they’re not part of that chain. How do we change this so the commits form a linear sequence again?
The simplest option is to use git-merge once more, but this will make your git history very hard to read, given that you’re likely to go through multiple rounds of code review, each one potentially requiring a series of merges.
Another solution is to use git-rebase. Starting with the lowest-but-one feature branch (f2 in this case), we rebase each branch against the branch below it. Here’s what that looks like:
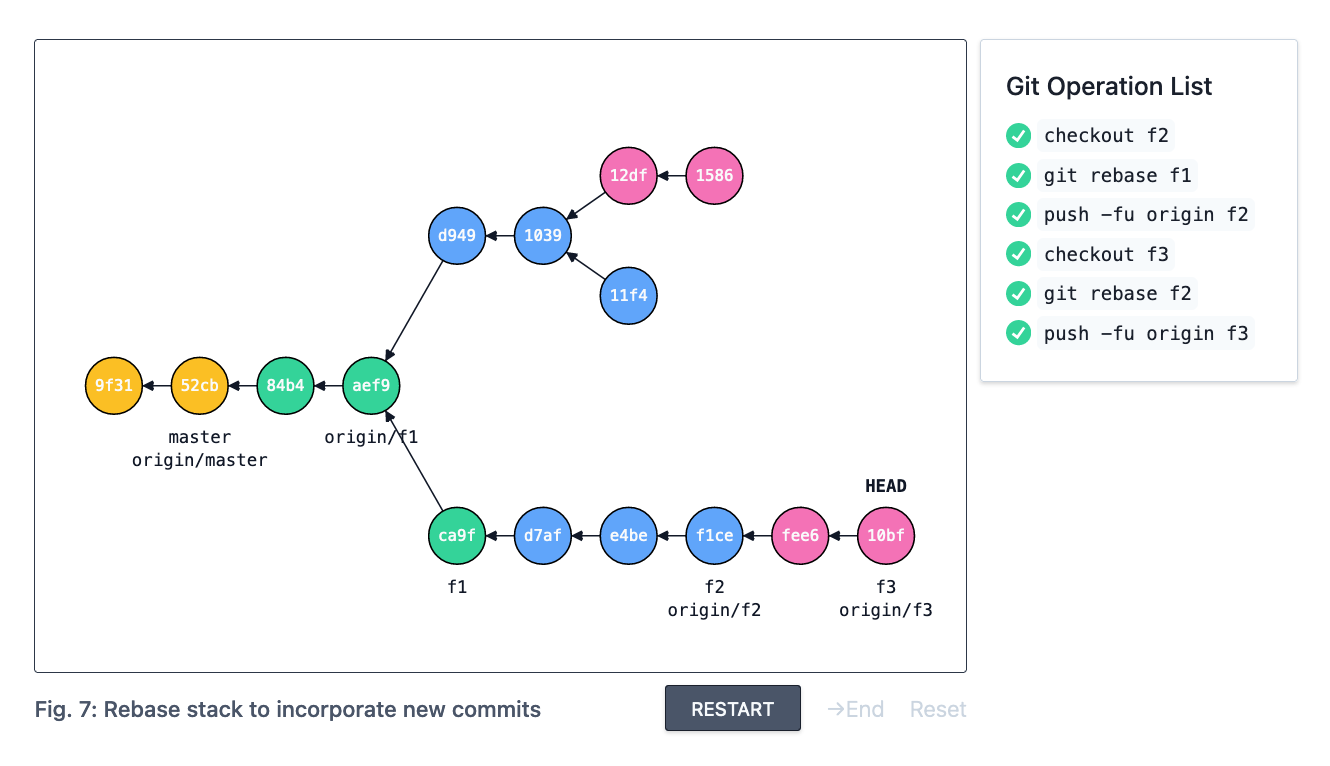
This takes you back to having a linear chain of commits. Note that the use of git-rebase also requires a force push, because we’re moving the branch pointers f2 and f3 to entirely new commits.
So far so good! You can use a sequence of rebases like this to keep your stack of PRs in sync during a code review.
This is good enough in some cases, but there’s one glaring issue with this approach - it can’t handle conflicts.
git-rebase includes a deduplication mechanism to help it avoid picking duplicate commits, but this doesn’t work well with conflicted commits.
Rebase Deduplication
Let’s go over everything that git does when you run git rebase <branch_name>:
- Make a list of all commits that are reachable from
HEADbut not from<branch_name> - Hard reset the current branch pointer so it points to
<branch_name> - Consecutively apply each commit from Step 1
Here’s a description of Step 3 (“Consecutively apply each commit”) from the git-rebase docs:
The commits that were previously saved into the temporary area are then reapplied to the current branch, one by one, in order. Note that any commits in
HEADwhich introduce the same textual changes as a commit inHEAD..<upstream>are omitted (i.e., a patch already accepted upstream with a different commit message or timestamp will be skipped).
git-rebase deduplicates commits based on their content instead of SHA, so the two duplicate commits are elided.
What happens when a rebase encounters conflicts? Once you resolve the conflicts, does the deduplication logic still work? Unfortunately for us, the answer is no. Once a conflict occurs (and is resolved), the two commits in question don’t have the same contents anymore, so git rebase’s deduplication heuristic fails, leaving us with this series of commits:
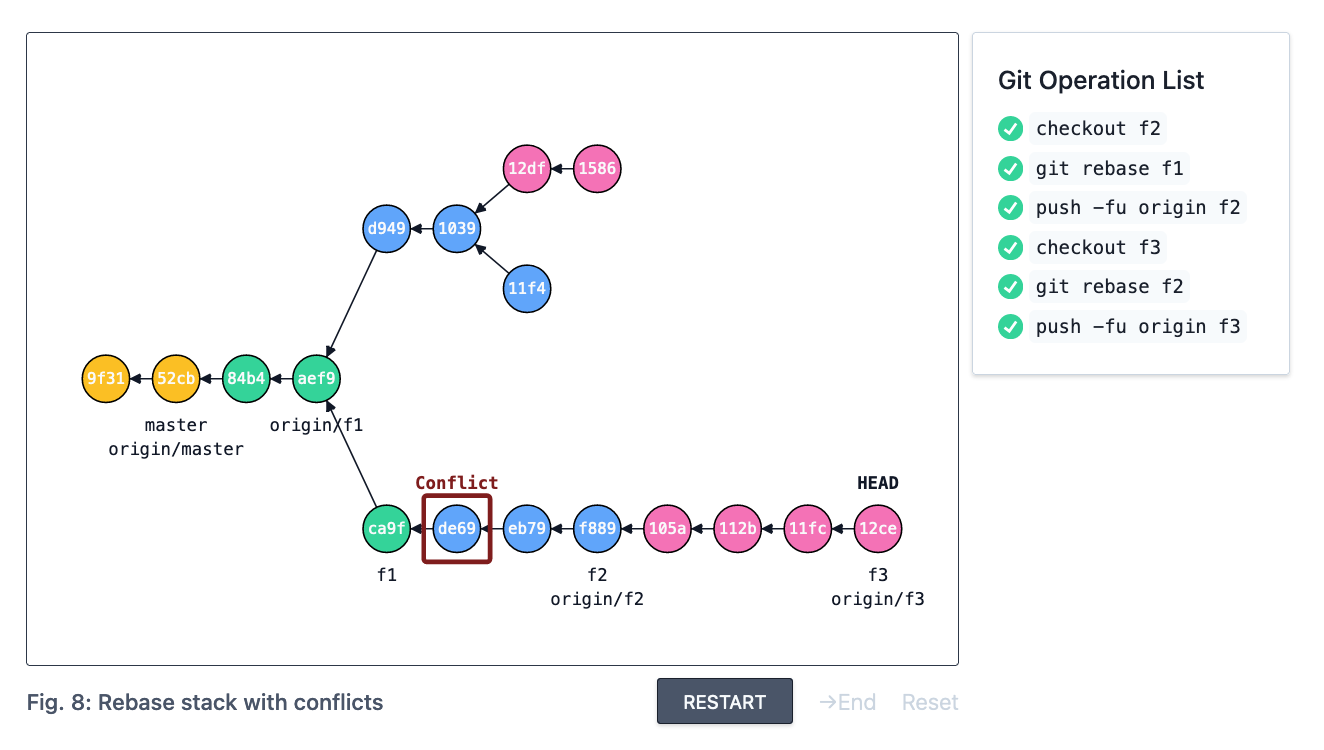
Note that we start with two pink commits, but end with four! The upshot is that their textual content doesn’t match anymore. When git rebase f2 is creating a list of commits to apply, it picks all commits because the conflict thwarts its deduplication logic, leading to commits being reapplied (which typically leads to further conflicts + general sadness in practice).
This is the main problem with the stacked PR workflow. When you make changes that cause conflicts, git-rebase attempts to pick the same commit multiple times, which makes repairing the stack hard-to-impossible. You’re left with duplicated commits, further conflicts, and no easy way to proceed.
There’s a better way to think about stacked PRs that avoids this problem entirely, though, which I’ll go into next.
A Better Way
Here’s the core idea: start on master, and cherry-pick every commit from each of your branches one-by-one, in order. You fix conflicts along the way, and this doesn’t affect any subsequent cherry-picks. As you’re cherry-picking, move each branch pointer over to the new chain of commits. Here’s what this looks like:

Note that branches aren’t pushed up to GitHub during the entire cherry-pick operation. This is because the origin/* branches conveniently serve as markers for the boundary of each cherry pick. You can even generalize this as:
- For a given feature branch
xthat was branched off from branchy - The set of commits representing
xis given byorigin/y..x
Double-Dot Syntax
If you aren’t familiar with this double-dot syntax, git uses it to select commit ranges. In the context of a cherry-pick, a..b means:
- Starting with the commit after
a - Cherry-pick commits one by one
- Until you reach
b(inclusive)
The book goes into this in a bit more depth.
Once the stack has been repaired with this sequence of cherry picks, we can push all branches up to GitHub all at once with:
$ git push -f origin f1:refs/heads/f1 f2:refs/heads/f2 f3:refs/heads/f3This is really all there is to the improved stacked PR workflow. I’ve used this for a few months now and haven’t run into any issues with it, even with largish stacks of PRs rife with conflicts.
Managing all this metadata by hand is extremely annoying, though, which brings us to…
Tooling
The simplest way to automate a lot of this workflow is a simple shell script. Here’s a script to repair a stack using the cherry-pick strategy outlined above. It reads in a list of feature branches (in stack order, from lowest to highest) from a file, and repairs the stack:
#!/usr/bin/env bash
git checkout --detach master
BOUNDARY="origin/master"
PUSH=""
while read line; do
git cherry-pick "$BOUNDARY".."$line"
git branch --force "$line"
BOUNDARY="origin/$line"
PUSH="$PUSH $line:refs/heads/$line"
done
git push -f origin "$PUSH"There are two problems with this script:
- It needs a list of branches in the stack to be passed to it, which is annoying to build & maintain.
- It can’t pause when a conflict occurs, so you have to fix the conflict and (somehow) re-run it from the point it stopped at, which is fiddly at best.
gh-stack
I wanted to not have to worry about this sort of thing, so I wrote a tool - gh-stack - which handles all the annoying bits about this workflow.
Given an identifier that’s unique to a given stack of PRs, it looks for all PRs with that identifier in the title (using the GitHub API), and builds a dependency graph to figure out which PR merges into which. I typically use a Jira ticket number as the identifier.
Once it has this dependency graph built up, it can do two things:
1. PR Annotation
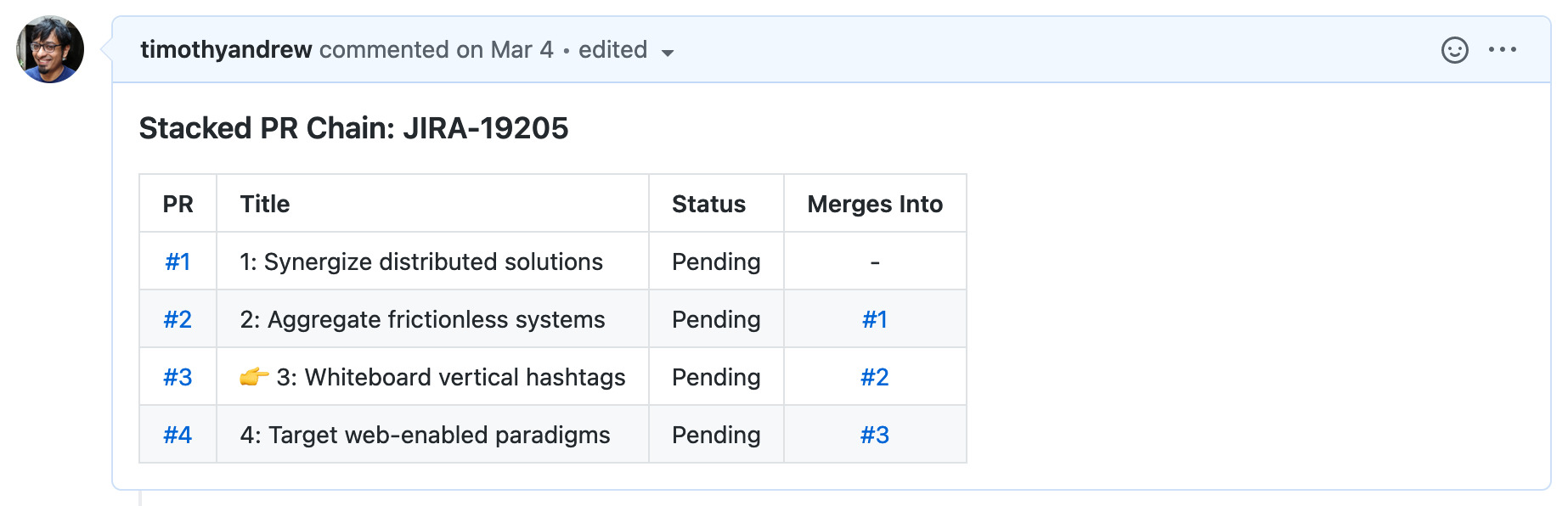
gh-stack will add a (markdown) table to the description of each PR in the stack with a list of all PRs in the stack. This helps you get your bearings quickly when you’re at a PR page but aren’t sure where in the stack that PR fits.
First, set up the PR stack on GitHub so each PR contains “JIRA-19205” in the title. Once it’s authenticated with GitHub, gh-stack can now show you a list of PRs in the stack:
❯ export GHSTACK_OAUTH_TOKEN=<github_personal_access_token>
❯ gh-stack log JIRA-19205
#1: [JIRA-19205] 1: Synergize distributed solutions (Base)
#2: [JIRA-19205] 2: Aggregate frictionless systems (Merges into #1)
#3: [JIRA-19205] 3: Whiteboard vertical hashtags (Merges into #2)
#4: [JIRA-19205] 4: Target web-enabled paradigms (Merges into #3)Next, annotate the PR descriptions:
❯ gh-stack annotate JIRA-19205
1: [JIRA-19205] 1: Synergize distributed solutions
2: [JIRA-19205] 2: Aggregate frictionless systems
3: [JIRA-19205] 3: Whiteboard vertical hashtags
4: [JIRA-19205] 4: Target web-enabled paradigms
Going to update these PRs ☝️ Type 'yes' to continue: yes
Done!This adds a “Stacked PR” section to the description of every pull request in the stack, like so:
This is set up to be idempotent, so running annotate multiple times will replace an existing annotation if it exists, instead of appending multiple tables to the PR description.
2. Stack Repair
The other thing gh-stack does is to repair a given stack of PRs using the same cherry-pick strategy described above, but a lot more intelligently than the shell script does. Given a stack of PRs, you can repair the stack with:
$ gh-stack autorebase -C $(pwd) -b <SHA> <identifier>where -C is the path to the repo, and -b is the boundary for the very first cherry-pick (typically this is origin/master).
This checks out the ref that -b denotes, and starts cherry-picking commits for each feature branch, one by one. Note that the unique identifier is all you need to provide - there’s no need to remember the names of all the branches you’re dealing with.
When a cherry-pick encounters conflicts, gh-stack pauses and lets you resolve the conflicts (by marking resolutions with git add). Once that’s done, it unpauses and continues cherry picking its way up the stack.
Local branches are updated at the very end, so aborting an ongoing autorebase doesn’t leave your repository in a messy/inconsistent state.
I’ve used gh-stack autorebase dozens of times in the last few months, and it’s a significant boost to productivity. I’ve used it to manage stacks of PRs that are 5-12 PRs/branches in length, and it’s been comfortable. Once I’ve made changes to the branches in a stack, getting the entire stack back into a good state (single linear set of commits) is literally a few seconds’ work.
Tradeoffs
The stacked PR workflow in general can be very useful, but it isn’t a silver bullet. There are concerns & tradeoffs to consider:
- You can’t create a stack of pull requests if you’re on a fork.
- Force-pushes are pretty much a requirement, so this doesn’t work well for collaborative feature branches.
- There’s more initial overhead for the author; it’s a lot easier (at first, anyway) to stick the entire change in the single PR.
Conclusion
Ultimately, stacking PRs is just another tool to help manage GitHub-based code review. I’ve found that it works well for large changes (4+ PRs), but small-to-medium changes are generally better off as commits on a single PR. There’s undoubtedly some discretion that needs to be applied here, but don’t be afraid to use a stack of PRs if the situation calls for it!
The tooling situation is not great, admittedly. I haven’t found another tool that does what gh-stack does, and there’s a lot of room for improvement there. I’m also hoping for something GitHub-native in the near future.
As for immediate next steps, I want to add functionality to gh-stack so it creates the initial set of PRs on Github for you. Right now you have to create them manually and make sure each PR has the right merges into value set, which can be somewhat error prone.
You can find the code for all the visualizations in this post here, and here’s the gh-stack repo once again.