XV6 Book
Notes
- hart == core
- This code is very non-portable; how much work would it be to get it to also run on x86, say?
Chapter 1: Operating System Interfaces
-
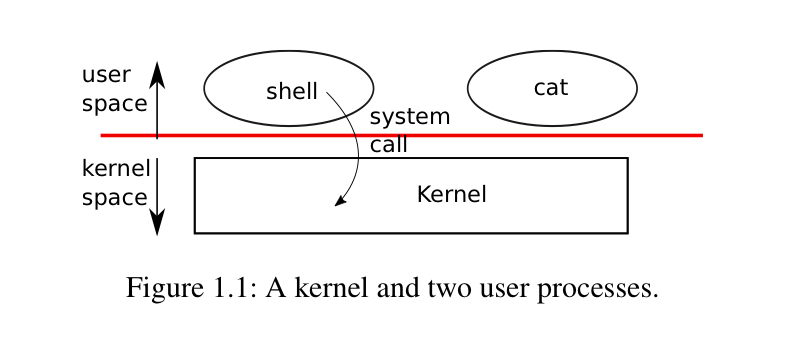
-
The fact that the shell is a user program, and not part of the kernel, illustrates the power of the system call interface: there is nothing special about the shell.
-
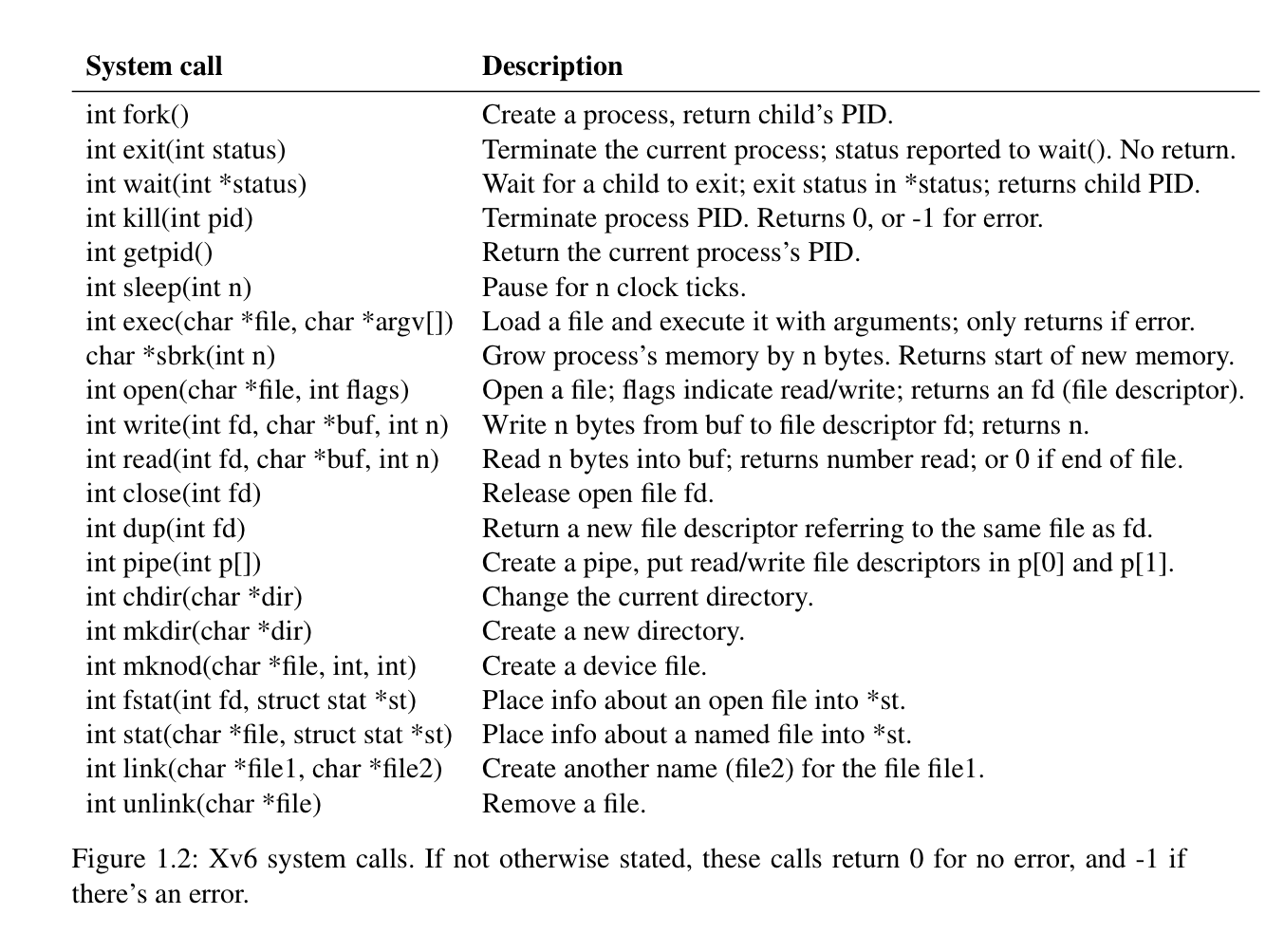
-
fork/exec
-
ELF for executables
-
The xv6 shell waits for a command, forks, the parent waits, and the child execs the command
-
File descriptors are namespaced by process
-
Forking copies the FD table
-
0: stdin, 1: stdout, 2: stderr
-
FDs are assigned in order - always the lowest unused integer for a given process ID
-
IO redirection:
- Fork
- Close FD 0, 1, or 2 (or some combination)
- Open as many files as were closed; these will be given FDs 0, 1, or 2 depending on which ones were closed
- Exec the program, which has no idea that the “std” FDs have been redirected
-
fork/exec aren’t combined into a single syscall so the shell can perform this sort of redirection in between
-
mknodto create a device file -
File is represented by one inode and potentially many names (links)
-
cdneeds to be built into a shell, because changing the working directory in a forked child would have no visible effect -
The file system and file descriptors have been powerful abstractions. Even so, there are other models for operating system interfaces. Multics, a predecessor of Unix, abstracted file storage in a way that made it look like memory, producing a very different flavor of interface. The complexity of the Multics design had a direct influence on the designers of Unix, who tried to build something simpler.
Chapter 2: Operating System Organization
-
CPUs provide hardware support for strong isolation. For example, RISC-V has three modes in which the CPU can execute instructions: machine mode, supervisor mode, and user mode.
- machine mode is used to set things up, presumably on boot
- supervisor mode can execute privileged instructions <- kernel
- user mode <- all userspace applications
-
CPUs provide a special instruction that switches the CPU from user mode to supervisor mode and enters the kernel at an entry point specified by the kernel. (RISC-V provides the ecall instruction for this purpose.)
-
Kernel types;
-
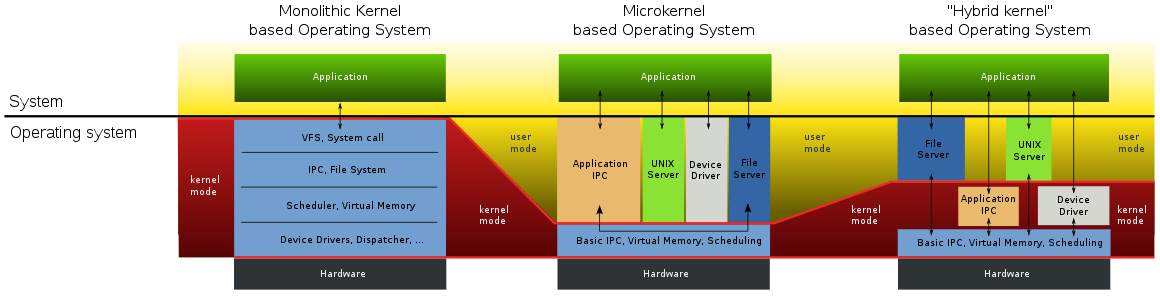
- Monolithic: entire OS runs in supervisor mode
- Microkernel: most of the OS runs in user mode
-
-
the process abstraction provides the illusion to a program that it has its own private machine
-
xv6 virtual memory
-
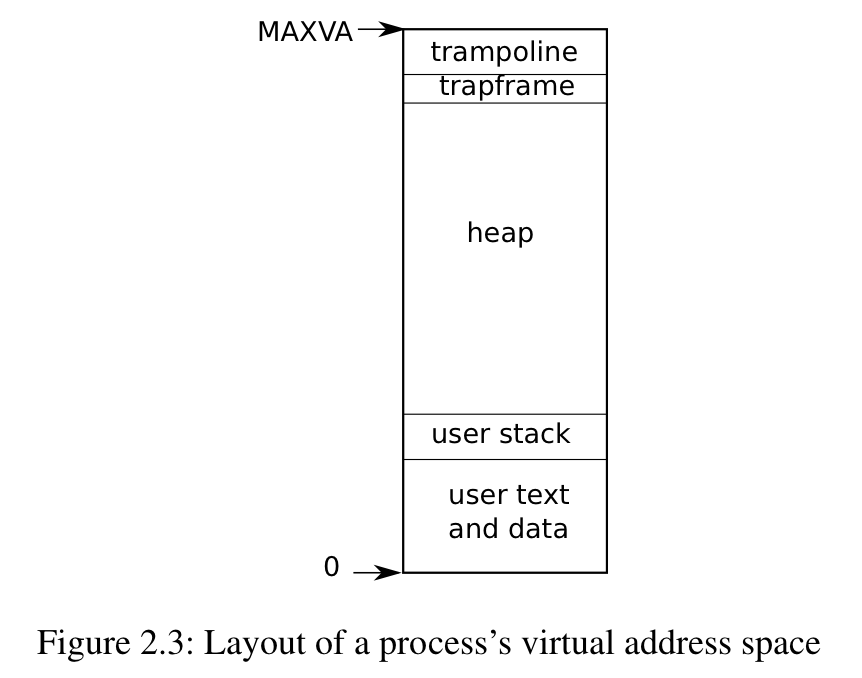
-
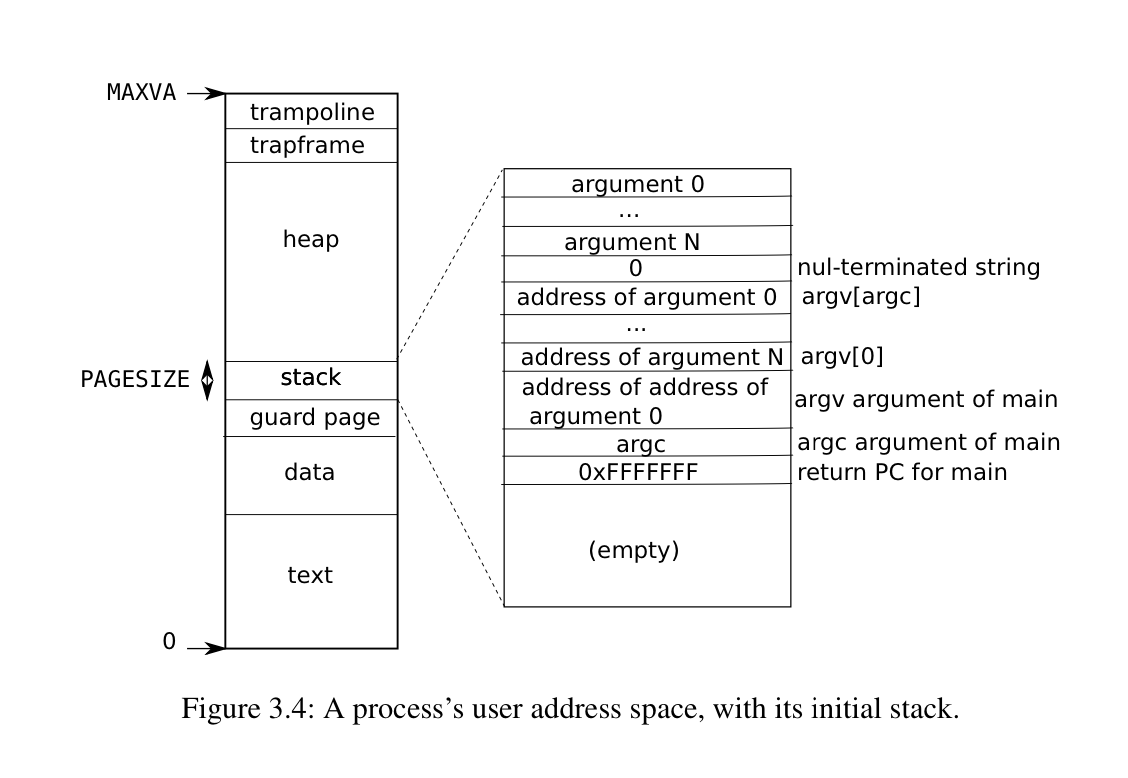
Instructions come first, followed by global variables, then the stack, and finally a “heap” area (for malloc) that the process can expand as needed.
-
At the top of the address space xv6 reserves a page for a trampoline and a page mapping the process’s trapframe to switch to the kernel.
-
-
The kernel maintains state for each process, including its page table, kernel stack, and run state
- Run state: whether the process is allocated, ready to run, running, waiting for IO, or exiting
- Every process also maintains a user stack, but the kernel stack is only accessible from kernel space
-
Boot
- RISC-V computer runs boot loader
- Boot loader loads the kernel into memory at 0x80000000 (no virtual memory yet)
- Kernel is executed (entry.S)
- A stack is set up at
stack0+4096 - The C entrypoint is invoked (
start.c) - The C entry point switches (from machine mode) to supervisor mode using
mretand executesmain.c maincallsuserinit(proc.c), which executesinitcode.Sin user spaceinitcode.Susesexecto run the/initprogram- The system is up
-
A syscall like
cloneis required to support multi-threaded processes (xv6 doesn’t) -
Chapter 3: Page Tables
-
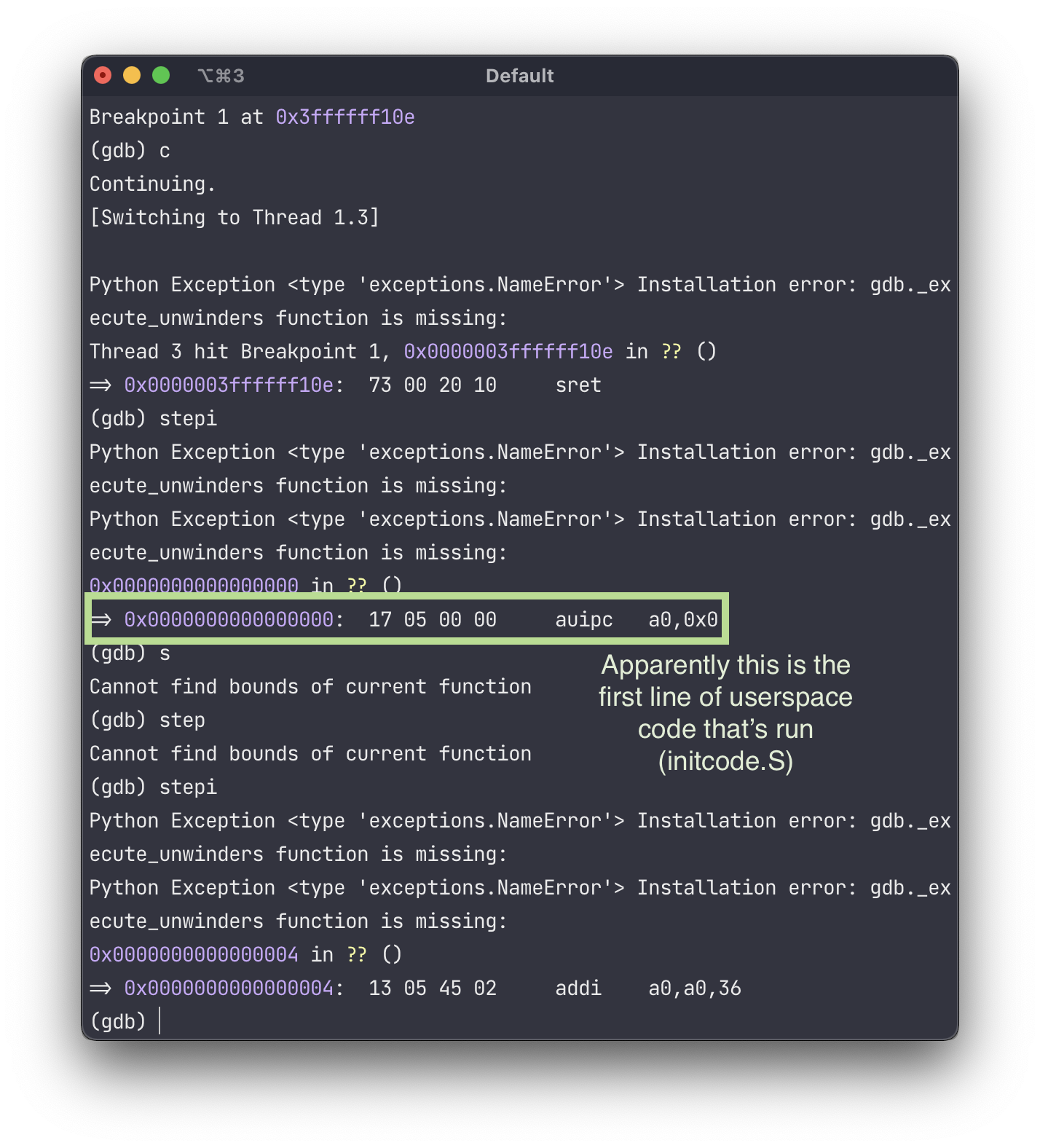
xv6 uses RISC-V’s “sv39” paging scheme, which only uses 39 bits of each virtual address
-
$2^{27}$ page table entries, each pointing to a physical start-of-page address that uses 44 bits
- The top 27 bits of the (39-bit) virtual address are used to index into a page table entry
- The remaining 12 bits are appended to the 44-bit physical page address - this is the complete physical address
- This implies that each page can be completely addressed using 12 bits, and so uses 4096 bytes
- Maximum addressable memory is $2^{27} * 4096$ bytes, which is ~550GB
-
-
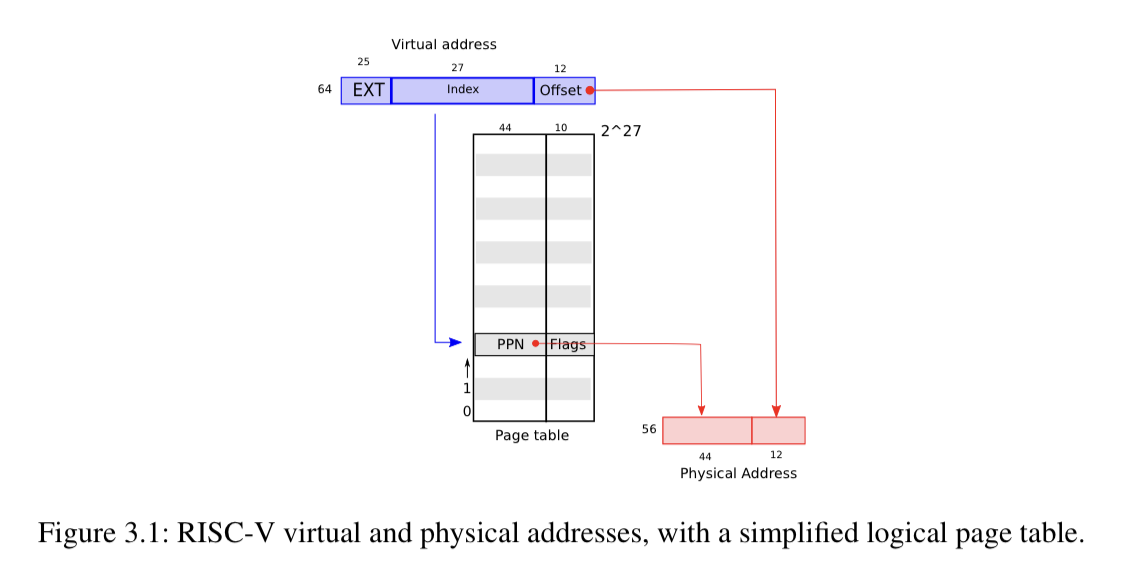
The actual page table is implemented as a 3-level tree
- Rooted at a single 4096-byte page that contains physical addresses for similar pages in the second level of the tree.
- Each second level page does the same for a third level
- Each page contains 512 page table entries, so the 27-bit virtual address is split into three 9-bit chunks, each of which addresses a 512-entry page table
- Each leaf page contains the actual mapping to the physical address
- I assume this is an optimization to store a large lookup table in 4096-byte chunks
- The page table is stored in physical memory; the CPU expects to find a page table matching this structure at the memory address in
satp(which is a register, so each CPU can point to a different page table) - How much space efficiency is lost by having so many more physical addresses recorded than necessary?
- Is this entire structure allocated lazily or eagerly?
- I’m assuming lazily, because this structure uses one page at the first level, 512 pages at the second level, 262,144 pages at the third, and 262,657 pages in total, which will take up 1.07GB if allocated in full.
- Yep: “This three-level structure allows a page table to omit entire page table pages in the common case in which large ranges of virtual addresses have no mappings.”
-
-
Referencing a page table entry that doesn’t exist causes a page fault
-
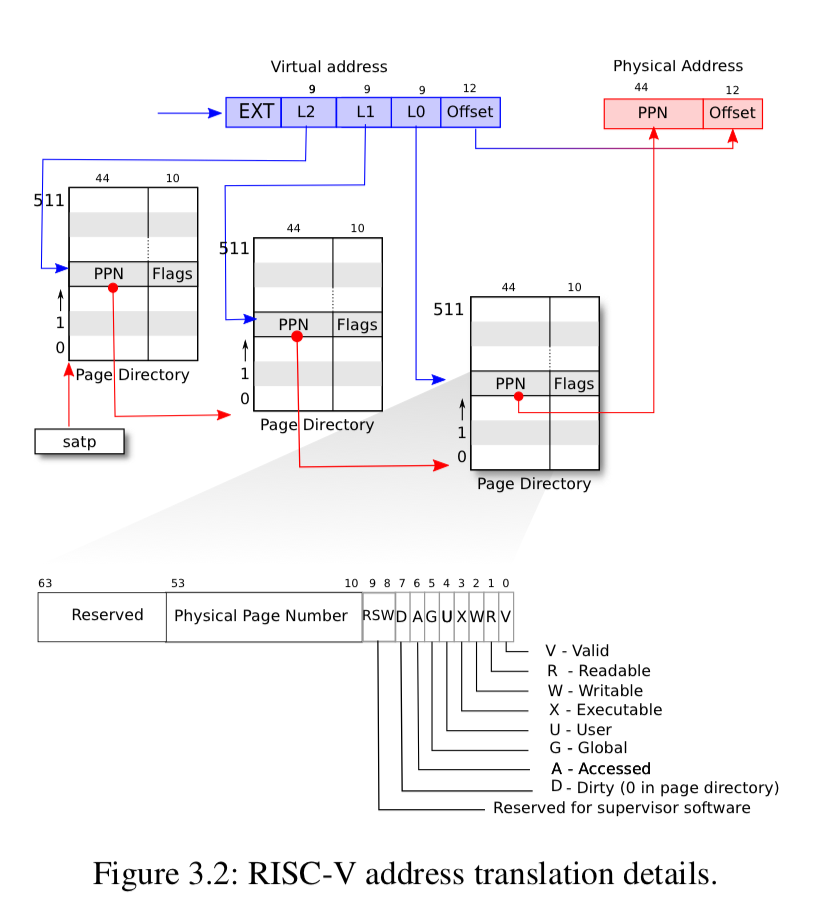
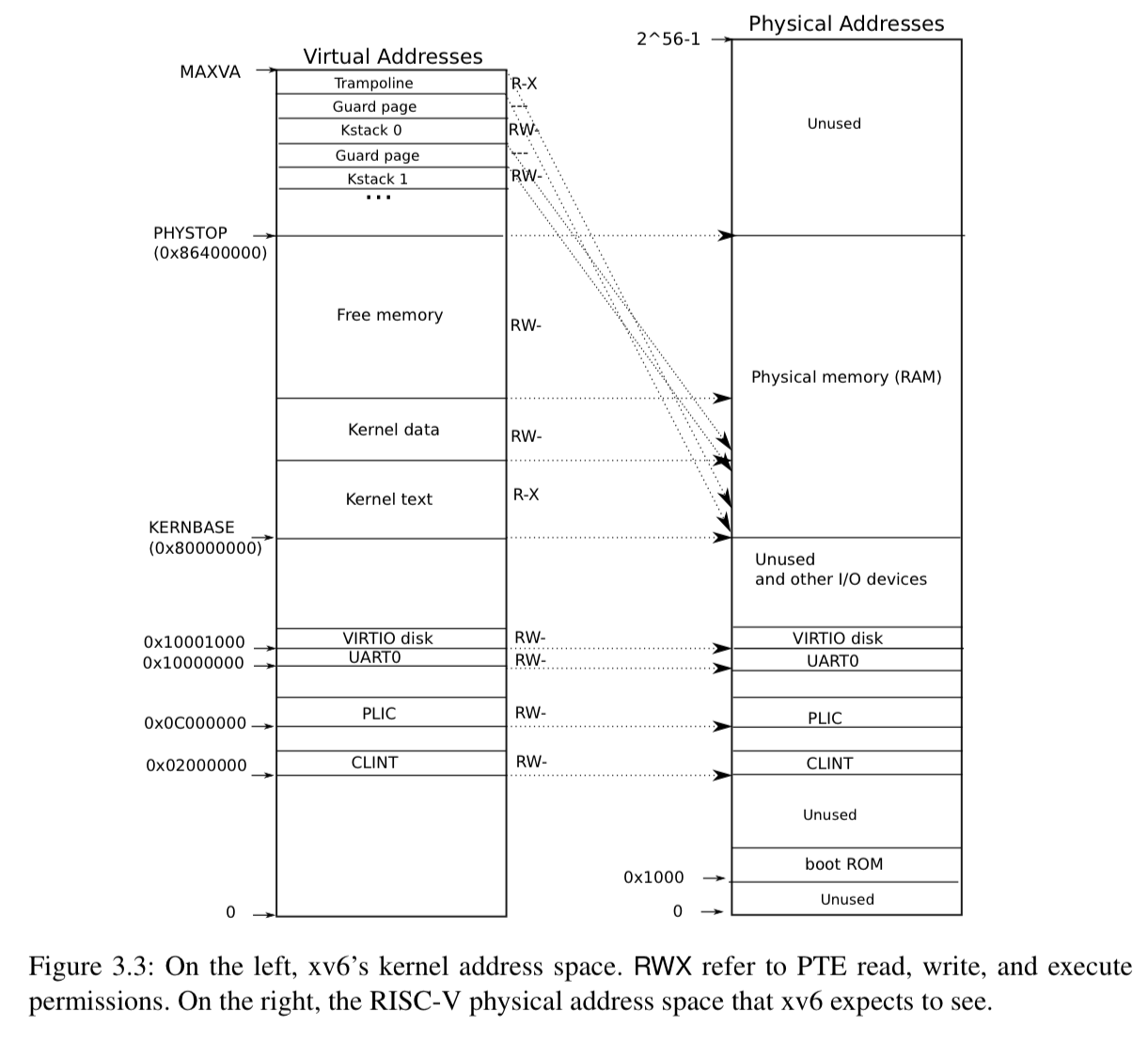
xv6 maintains one page table per process + one for the kernel itself
- The kernel page table is set up to match physical memory (almost) exactly, with a few exceptions:
- The trampoline page is mapped both at the end of kernel’s virtual address space and directly mapped at the physical location
- Each process has its own kernel stack, these are mapped high in the virtual address space, and each is bounded by a guard page to guard against overflows.
- Guard pages are marked “invalid” so an overflow causes a page fault instead of silently overwriting memory
-
- The kernel page table is set up to match physical memory (almost) exactly, with a few exceptions:
-
QEMU makes virtual devices available as memory-mapped control registers at physical addresses below 0x80000000; the kernel interacts with these devices by writing to these areas of memory
-
vm.ccontains code to manipulate page tableskvmfunctions manipulate the kernel page tablekvmmakesets up the kernel page table “manually”-
uvmfunctions manipulate user page tables
-
walk mimics the RISC-V paging hardware as it looks up the PTE for a virtual address. walk descends the 3-level page table 9 bits at the time. It uses each level’s 9 bits of virtual address to find the PTE of either the next-level page table or the final page.
If the PTE isn’t valid, then the required page hasn’t yet been allocated; if the alloc argument is set, walk allocates a new page-table page and puts its physical address in the PTE. It returns the address of the PTE in the lowest layer in the tree
-
procinitallocates a kernel stack for each process -
Page table entries are cached in a (per-CPU) TLB (translation look-aside buffer)
- Changes to the page table must explicitly invalidate those entries in the TLB
- The
sfence.vmainstruction flushes the TLB - How large is the TLB? What eviction strategy is used when it becomes full?
-
kalloc.cis a physical memory allocator-
When initialized it “frees” all pages from the end of the kernel to
PHYSTOP(128MB from the start) -
The allocator sometimes treats addresses as integers in order to perform arithmetic on them (e.g., traversing all pages in freerange), and sometimes uses addresses as pointers to read and write memory (e.g., manipulating the run structure stored in each page); this dual use of addresses is the main reason that the allocator code is full of C type casts. The other reason is that freeing and allocation inherently change the type of the memory.
-
When a process asks for memory (via the
sbrksyscall),kalloc(possibly repeatedly) removes a page from the free list and makes it available, and xv6 then adds it to the process' page table viamappages.
-
-
xv6 user process stacks are limited to being a single page in size, and are bounded with a guard page:
-
-
Exec allocates a new page table with (initially) no mappings
-
Each executable segment in the (ELF) executable is loaded into memory at virtual addresses specified in the executable
-
Users or processes can place whatever addresses they want into an ELF file. Thus exec is risky, because the addresses in the ELF file may refer to the kernel, accidentally or on purpose. The consequences for an unwary kernel could range from a crash to a malicious subversion of the kernel’s isolation mechanisms (i.e., a security exploit).
In an older version of xv6 in which the user address space also contained the kernel (but not readable/writable in user mode), the user could choose an address that corresponded to kernel memory and would thus copy data from the ELF binary into the kernel.
In the RISC-V version of xv6 this cannot happen, because the kernel has its own separate page table; loadseg loads into the process’s page table, not in the kernel’s page table.
-
How does this work in conjunction with ASLR?
-
-
Super pages: *
On machines with lots of memory it might make sense to use RISC-V’s support for “super pages.” Small pages make sense when physical memory is small, to allow allocation and page-out to disk with fine granularity. For example, if a program uses only 8 kilobytes of memory, giving it a whole 4-megabyte super-page of physical memory is wasteful. Larger pages make sense on machines with lots of RAM, and may reduce overhead for page-table manipulation.
Chapter 4: Traps & System Calls
-
Trap triggers
- System call (
ecall) - Hardware interrupt
- Exception (divide by zero, invalid/illegal instruction, etc.)
- System call (
-
RISC-V allocates (supervisor-mode) registers for trap configuration:
- RISC-V jumps to the address in
stvecto handle a trap sepccontains the address that was jumped from when a jump tostvecoccursscauseis set to a code representing the reason for the trapsscratchis used to hold a pointer to the hart-local supervisor context while the hart is executing user codesstatusis a bit-field containing supervisor-mode configuration:-
- RISC-V jumps to the address in
-
During a context switch, the only user-mode register the hardware saves/changes is
pc; all other registers are handled by the kernel -
Path of a trap from user space
uservec(trampoline.S) ← this is the address saved tostvecusertrap(trap.c)usertrapret(trap.c)userret(trampoline.S)
-
The
satpregister points to the currently-active page table in memory -
satpisn’t changed during a trap- So the usermode page table must contain a mapping for
uservecso it can start executing. uservecthen switchessatpto point to the kernel page table.- This switch shouldn’t cause inconsistencies (
pcshouldn’t jump forward or backward, for example), so the kernel page table must also contain a mapping foruservecat the same (virtual) address as the usermode page table. - xv6 uses a trampoline page, mapping it at the same virtual address in the kernel page table and all user page tables.
- So the usermode page table must contain a mapping for
-
There’s a bit more juggling involved with
sscratch- When
uservecstarts executing, it immediately swaps the first user register (a0) withsscratch. sscratchwas previously (just before the switch to user mode) set to a per-processtrapframe, which has space to store (among other things) all user registers in memorysatpstill points to the user page table, and crucially we can’t do anything about this - we can’t switch it to the kernel page table without preserving the old value first, but there’s nowhere we could store that value yet!- So this means the
trapframefor a given process needs to be mapped in that process' user page table uservecsaves all registers totrapframe, and only then switchessatpto point to the kernel page table, and then callsusertrap
- When
-
This diagram from above should now make a bit more sense:
-
usertrapdetermines the cause of the trap and processes it- It updates
stvectokernelvecbecause interrupts use different handler while in kernel mode sepcis saved to the per-process state - a process switch may occur whenusertrapis executing, causingsepcto be overwritten- How would this work exactly? How can a process switch occur when the kernel is “busy” on this core?
- It updates
-
Once the trap has been processed,
usertrapretanduserretunwind the actions ofusertrapanduservecrespectively -
A calling convention is an implementation-level (low-level) scheme for how subroutines receive parameters from their caller and how they return a result
-
syscalllooks in a7 for the code for the syscall to execute-
When the syscall is done, the return value is placed in a0
-
Executing the syscall is as simple as:
p->trapframe->a0 = syscalls[num](); -
This value becomes the return value to the userspace function that initiated the syscall, because the RISC-V calling convention for C puts return values in a0 (where is this defined? gcc/risc-v, I’m guessing)
-
-
usys.plgenerates userspace stubs for all syscalls which put the right code ina7and callecall- Arguments are handled by the C calling convention for RISC-V; the act of calling into the stub will put the arguments in registers starting at a0, which the kernel anticipates.
- What if a function takes more than 6 arguments?

Stopped at 4.5