The Tail at Scale
https://research.google/pubs/pub40801/
- Why does variability exist?
- Resources shared between different applications
- Daemons compete for resources but far less frequently
- Contention for global resources (distributed locks or file systems)
- Maintenance: normal operation is paused for compaction, garbage collection, etc.
- Queueing
- CPUs can throttle
- Disk-level GC can cause read perf to suffer even with a modest amount of write activity
- Enabling/disabling energy-saving modes isn’t instant
- Variability amplified by scale
- A service that’s only slow at p99 isn’t necessarily fast enough
- If each page load makes 100 requests to this service (either a webpage making tons of API calls or a single backend service fanning out to microservices), 63% of those page loads will be as slow as p99 for the backing service
- This gets worse the more you scale
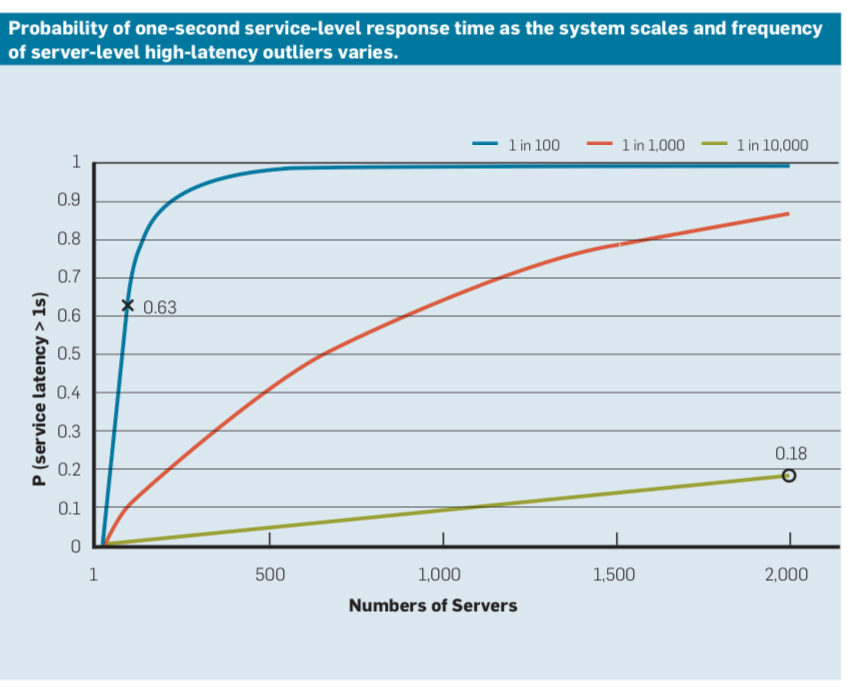
- Numbers from a real Google service

- Root server fans out requests, each child fans out again
- 50% of the p99 latency at the root is spent waiting for 5% of the fanned-out requests
- Reducing variability
- Prioritize interactive requests for resources
- Break big jobs apart to stop them negatively affecting the latency of smaller (possibly more time-sensitive) jobs
- Perform background activity at times of low traffic OR synchronize all servers so they perform background jobs at the same instant. This affects the latency of all the requests being processed that instant, but staggering them will affect all requests.
- Techniques to maintain decent perf in the face of variability
- Hedged requests
- Send requests to multiple replicas, use the first response you get
- Start by sending out a primary request, followed by secondary requests
- To avoid overloading all replicas, only start seconding secondary requests once the primary request has been delayed past the expected p95 latency
- Replicas can treat secondary requests as lower-priority than primary requests
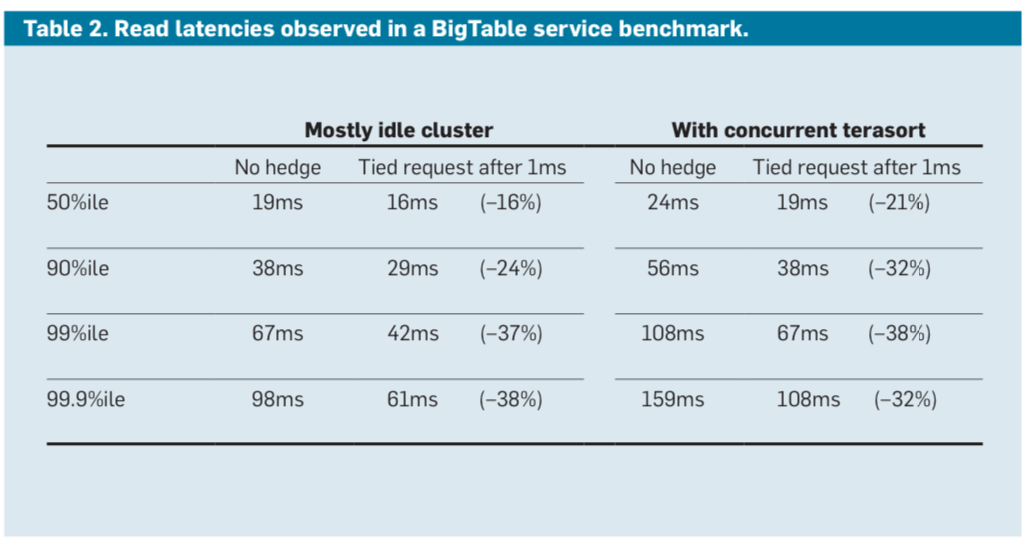
- Tied requests
- Send requests to two servers, each tagged with the other server’s address
- When a server starts executing the request, it tells the other server to cancel
- Send the second request after a delay of at least 2x the average network message delay to avoid both servers cancelling each other
- Is this really sufficient to avoid this problem?
- Benchmark
- Probe remote queues
- Peek at the request queues for all replicas, and send the request to the one with the shortest queue
- Hedged requests
- Long-term adaptations
- Micro-partitions
- More partitions than there are machines
- Dynamically assign partitions to machines
- Can shed load in smaller increments, and faster
- BigTable: 20-1000 partitions per machine
- Selective replication
- Store additional replicas of expensive/popular data
- Dynamic partition assignment can make sure that these hot replicas are placed evenly on all machines
- Probation
- Observe latency distribution of all replicas
- Put slow replicas on probation (until a temporary issue has passed, for example)
- Micro-partitions
- Large information retrieval systems
- Good-enough results quickly is better than the best results slowly