Spanner — Google’s Globally-Distributed Database
- PDF: https://static.googleusercontent.com/media/research.google.com/en//archive/spanner-osdi2012.pdf
- Questions
- What level is Colossus distributed at? Zone-wide? DC-wide?
- What does it mean to say each directory can have different replication settings? Shouldn’t all directories in a group have the same replication settings?
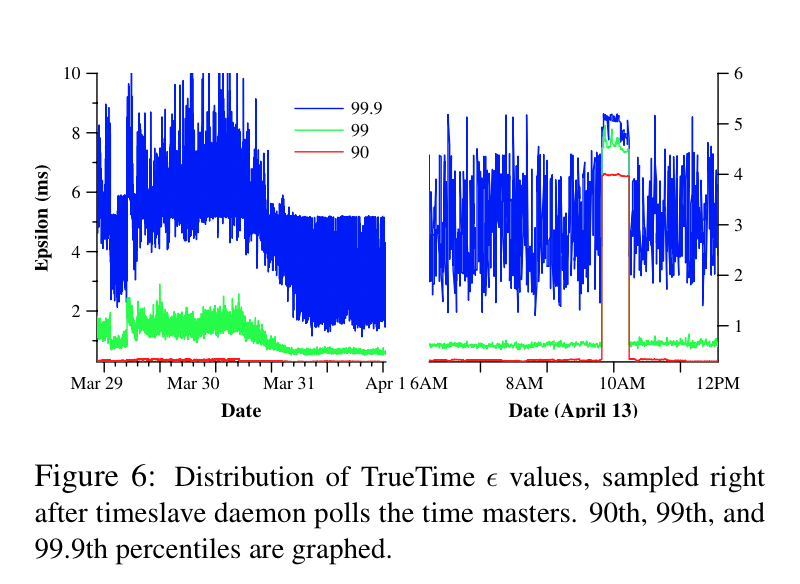
- TrueTime: how is network latency accounted for? Are we talking about the time the daemon recieved the request or the time the master received the request?
- How is the disjoint leadership (4.1.1) requirement enforced in the face of partitions (split brain)?
- What happens if a schema change is not done in time?
1. Introduction
- Globally-distributed database,
- The typical use case is to distribute to multiple datacenters in the same geographic region
- Latency degrades the closer you get to true “global” distribution
- Configurable replication with auto-failover
- Sharding + auto-resharding in the face of load pattern changes or failures, even between DCs
- Data is stored in semi-relational tables and is versioned, old versions are readable (by timestamp) if they haven’t been GCed
- Two important features that are traditionally difficult:
- Externally consistent reads and writes
- Globally consistent reads at a timestamp
- All transactions are fully serializable and each one is tagged with a timestamp representing its place in the total order
- Reads can use this timestamp (compared against a local timestamp confidence interval) to perform a strongly consistent read without having to contact the leader
- TrueTime API exposes clock uncertaintly, Spanner slows down if the uncertainty is large
2. Implementation
High-Level Architecture
-
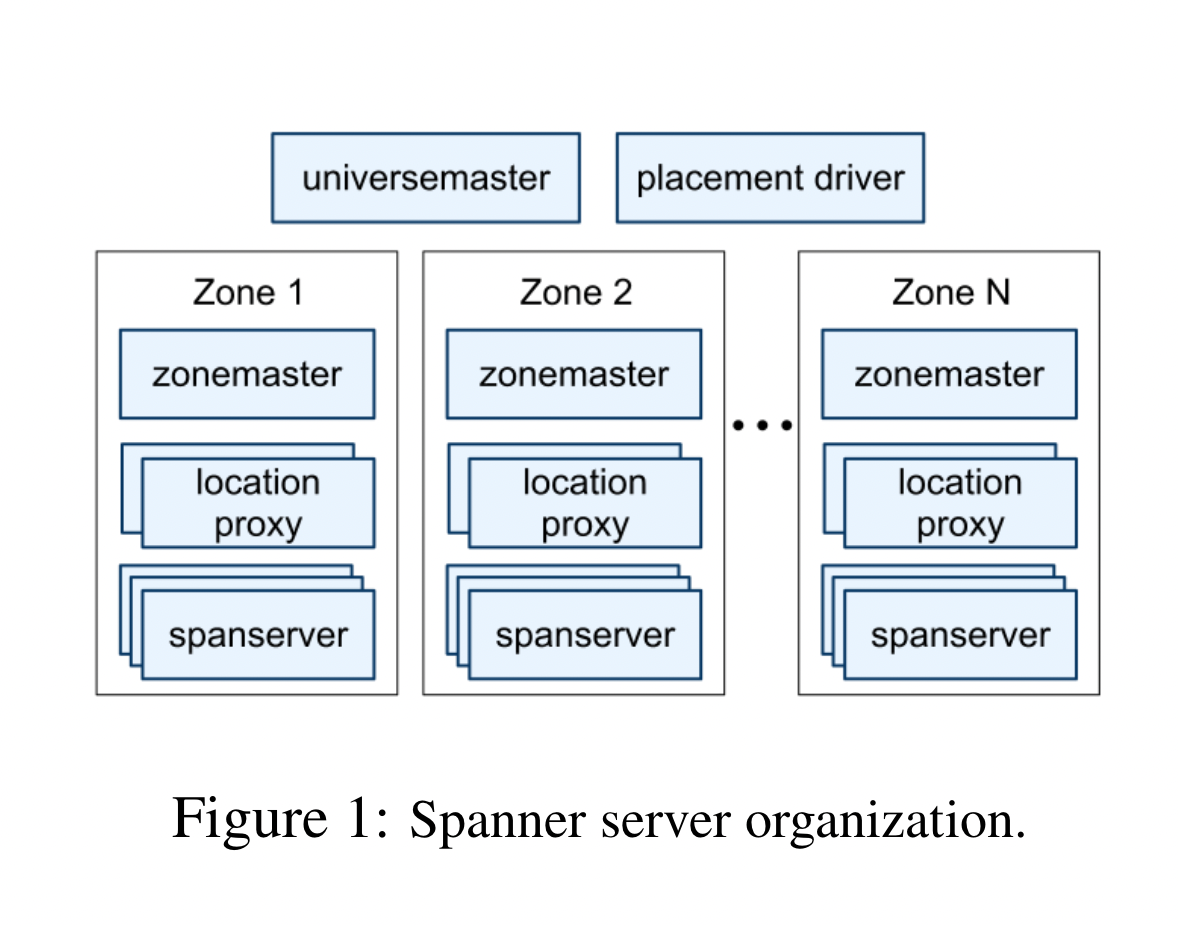
- Each deployment of Spanner is called a universe
- A universe is deployed across many zones, which are the locations where data can be replicated. One or more zones per DC.
- Each zone has a zonemaster and many spanservers (that serve data)
- A single universemaster for debugging/metrics and a single placement driver to handle resharding
- Data is sharded into directories, each of which contain
(key, timestamp) -> valuemappings. Data in directories share a common prefix. - Directories are placed into tablets, each of which forms a Paxos group across zones.
- Tablet data is stored in a distributed filesystem (Colossus, GFS’s successor), and is essentially the raw data in B-trees and a WAL.
Spanservers
- Spanservers are responsible for 100s-1000s of tablets, and for each, implement a Paxos state machine that connects all instances of this tablet across zones
-
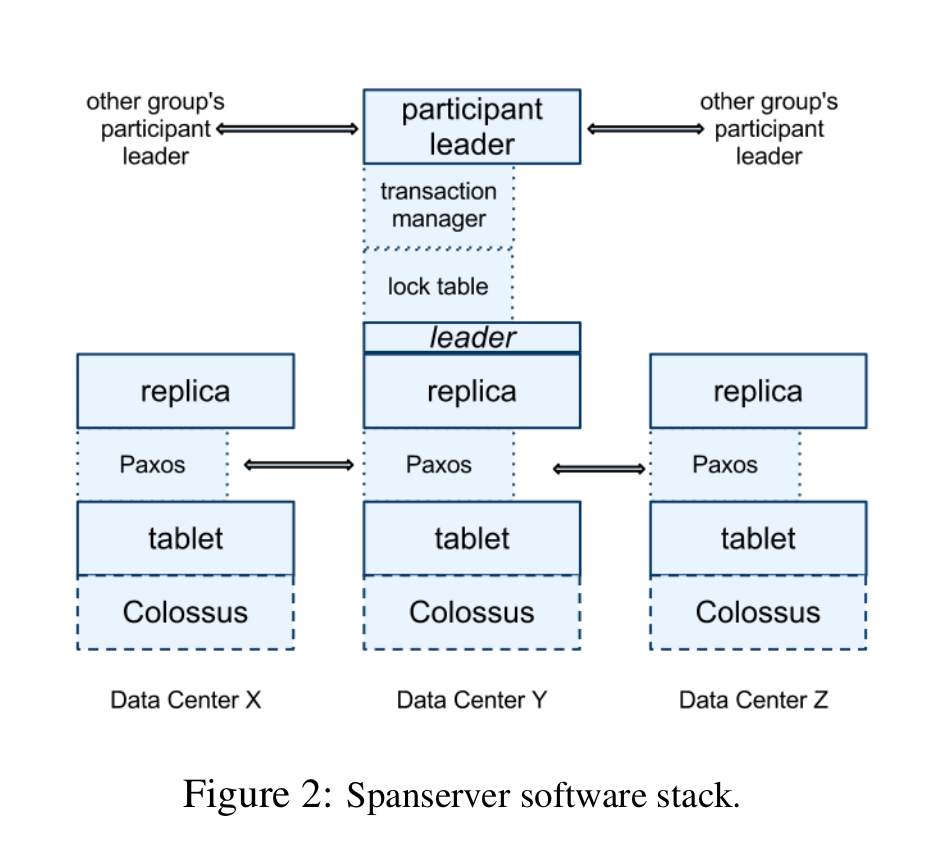
- Each Paxos group (or cluster) of tablets has a leader:
- All writes go through the leader
- Reads can go through any tablet that’s sufficiently up to date
- Leaders have a lock table that implements key range-level locking for safe concurrent access.
- Leaders also have a transaction manager, which forms a cluster with the leaders of all other groups (using Paxos?) for cross-group transactions using 2PC
Directories
- A directory is a set of contiguous keys that share a common prefix
- A directory is the unit of data placement; replication for each directory can be configured independently
- Resharding moves directories between groups to better balance load or to account for failure/etc.
- Directories can be moved online:
- Move almost all the data without creating a transaction
- Use a transaction to atomically move the last little bit over and update both the source and destination groups
- Directories are internally split into fragments if they get too large, and fragments are the real unit of data placement, but this is an implementation detail
Data Model
-
Some authors have claimed that general two-phase commit is too expensive to support, because of the performance or availability problems that it brings. We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions. Running two-phase commit over Paxos mitigates the availability problems.
-
The application data model is somewhat independent from the internal abstractions of the system:
- A universe has databases, which has (schematized) tables
- Tables look like relational tables: rows, columns, and versioned values
- Tables are divided up into directories
-
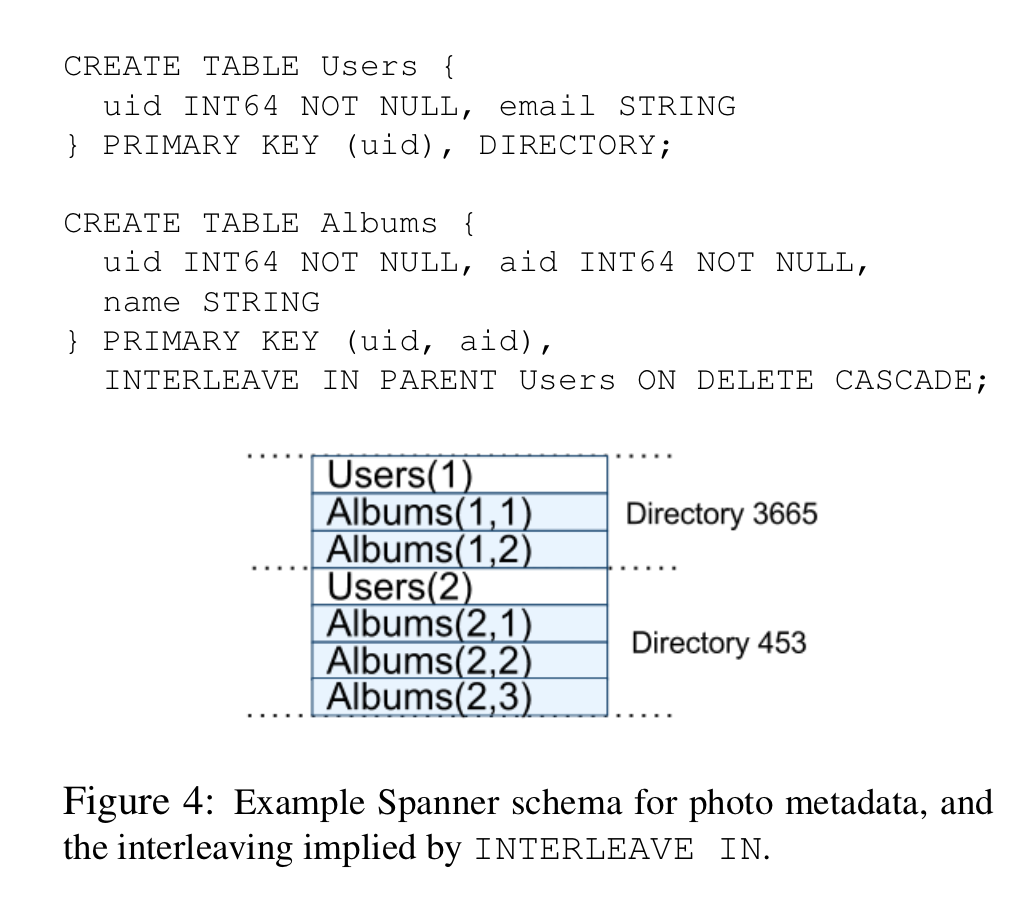
Each row must have at least one primary key, which is not a requirement for a strictly relational database
-
INTERLEAVE INto declare hierarchies: *Each row in a directory table with key K, together with all of the rows in descendant tables that start with K in lexicographic order, forms a directory
-
3. TrueTime
-
API:

-
The absolute time at which
TT.now()is called is guaranteed to be within the bounds returned by the call -
Uses two time sources (GPS and atomic clocks) internally for redundancy
-
A set of time master machines per datacenter and a time slave daemon per node
-
The majority of masters have GPS receivers with dedicated antennas; these masters are separated physi- cally to reduce the effects of antenna failures, radio in- terference, and spoofing. The remaining masters (which we refer to as Armageddon masters) are equipped with atomic clocks. An atomic clock is not that expensive: the cost of an Armageddon master is of the same order as that of a GPS master.
-
A daemon polls multiple masters to reduce error rate
4. Concurrency Control
- Three types of transactions: read-write, read-only, and snapshot reads
- Read-write transactions must hold locks before performing writes and all such transactions must happen at leader nodes
- Read-only transactions are read-write transactions that are declared to not have any writes. The system picks a timestamp and executes lock-free reads (MVCC?) against that timestamp.
- Snapshot reads are reads where the client specifies a particular timestamp (or a staleness bound) to perform the read at.
-
- For a given Paxos group, the time a given node spends as leader must be disjoint from the time all other nodes spend as leader
Choosing Timestamps
- Read-write transaction timestamps
- All timestamps between between the time all locks for the writes have been acquired and the time the locks are released are valid
- Spanner picks the timestamp that Paxos assigns to the Paxos write representing a commit
- Timestamps within a Paxos group must increase monotonically, even during leader changes
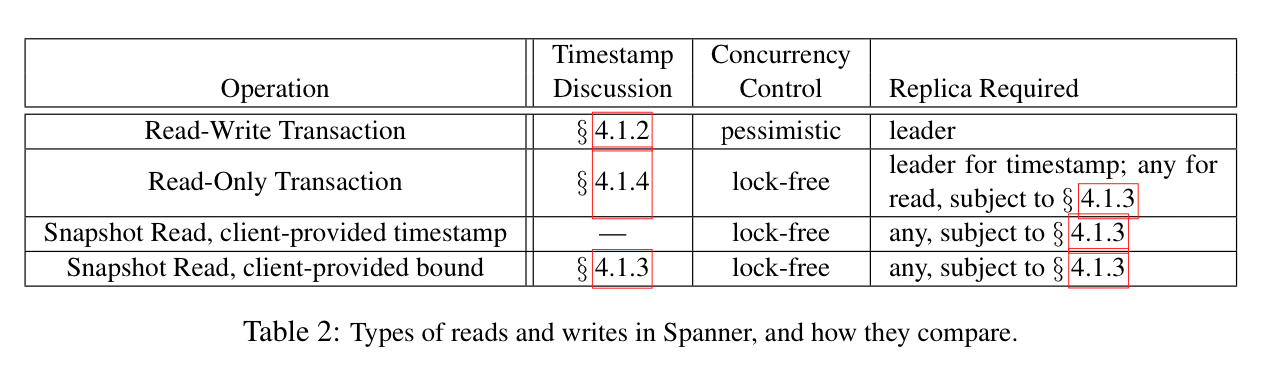
- If transaction $T_2$ starts after transaction $T_1$ ends, $T_2$’s commit timestamp must have a larger timestamp than $T_1$’s
- Say $s_i$ represents the commit timestamp of $T_i$, and $e_i^{start}$ & $e_i^{commit}$ represent the start and end commit events for $T_i$. The invariant ($e_2^{start} > e_1^{commit} \implies s_2 > s_1$) is enforced by:
- The leader assigns a commit timestamp $s_i$ that is
TT.now().latestor larger. The way TrueTime works, this timestamp is either the current timestamp or is in the future, but cannot be in the past. This ensures that $s_i > e_i^{start}$. - The leader then waits until
TT.now().earliestbecomes larger than $s_i$, which is a guarantee that the current time is greater than $s_i$. At this point the leader peforms the commit, which ensures that $s_i < e_i^{commit}$
- The leader assigns a commit timestamp $s_i$ that is
- More formally stated:
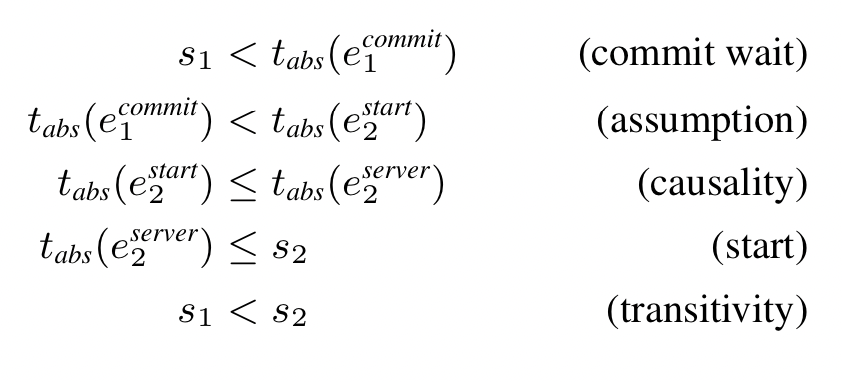
- What is the point of using true timestamps though? Why not use a monotonic counter and call it a day?
- In the context of a single Paxos group: say the leader is in NA and is accepting writes, and a reader wants to read from a replica in Europe. The typical method of ensuring a strongly consistent read is to insert the read as a write into the total order of events, wait for it to show up at the replica, and then peform a local read. This requires that reads turn into writes (readers block writers) in a system that’s already bottlenecked on writes, which is a problem. Using timestamps allows the reader to call
TT.now()and wait until the timestamp of the latest transaction at the replica has passed the bounds of theTT.now()call, at which point it performs a local read that’s guaranteed to be consistent. Reads don’t have to go to the group leader at all. - In the context of a transaction spanning multiple groups: Each group has a different leader, so using simple monotonic counters makes the transaction IDs for different leaders irreconcilable.
- In the context of a single Paxos group: say the leader is in NA and is accepting writes, and a reader wants to read from a replica in Europe. The typical method of ensuring a strongly consistent read is to insert the read as a write into the total order of events, wait for it to show up at the replica, and then peform a local read. This requires that reads turn into writes (readers block writers) in a system that’s already bottlenecked on writes, which is a problem. Using timestamps allows the reader to call
- How does a replica know how up-to-date it is ($t_{safe}$)? Usually this is just the timestamp of the most-recently-applied Paxos transaction, but this gets a bit more complex with distributed transactions (which may have written to Paxos but still be in a “prepare” state). In this case the latest timestamp that’s safe to read is the largest Paxos timestamp that has no uncommitted 2PC transactions behind it.
Implementation Details
- Read-write transactions across groups
- Reads can’t see uncommitted writes, even from the same transaction
- Rows that are read need to be locked too, and reads are performed before writes start
- Writes use 2PC
- The commit timestamp for the transaction is based on
TT.now()for all leaders participating in the transaction - Once the decision has been made, all participants apply/commit at the same timestamp and then release locks (presumably using the same waiting mechanism as above)
- Read-only transactions across groups
- The client determines
TT.now().latestand uses that absolute timestamp to perform reads against multiple replicas - This requires waiting, and Spanner can probably do better by negotating a “latest common timestamp” between all involved replicas, but this is unimplemented as of the paper’s writing
- The client determines
- Schema changes
- Changes to a database’s schema are semi-blocking but only at the level of a single Paxos group
- A schema-change transaction is assigned a timestamp $t$ that’s well into the future, but the actual change starts immediately
- All regular transactions with timestamp less than $t$ don’t have to block behind it
- Anything that must wait for the schema change simply waits until $t$ before issuing the change
- Spanner maintains a versioned schema: https://cloud.google.com/spanner/docs/schema-updates
5. Evaluation
-
These measurements were taken on timeshared machines: each spanserver ran on scheduling units of 4GB RAM and 4 cores (AMD Barcelona 2200MHz). Clients were run on separate machines. Each zone contained one spanserver. Clients and zones were placed in a set of datacenters with network distance of less than 1ms. (Such a layout should be commonplace: most applications do not need to distribute all of their data worldwide.)
-
2PC:
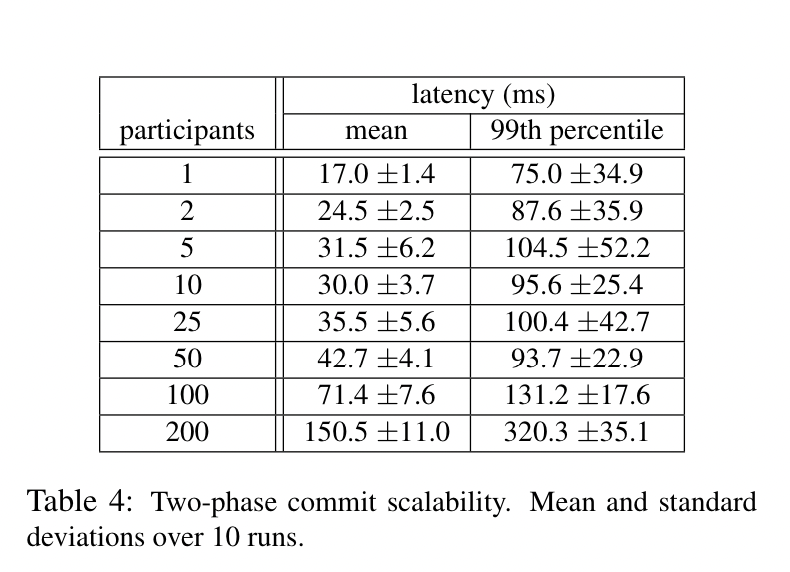
- I wonder how badly this degrades with a WAN between nodes
-