Raft - In Search of an Understandable Consensus Algorithm
- Original Paper: https://raft.github.io/raft.pdf
- Implementation: 6.824 Lab 2 - Raft
- Lectures
Introduction
-
Understandability was an important top-level goal while designing Raft.
-
Consensus algorithms allow a collection of machines to work as a coherent group that can survive the failures of some members.
-
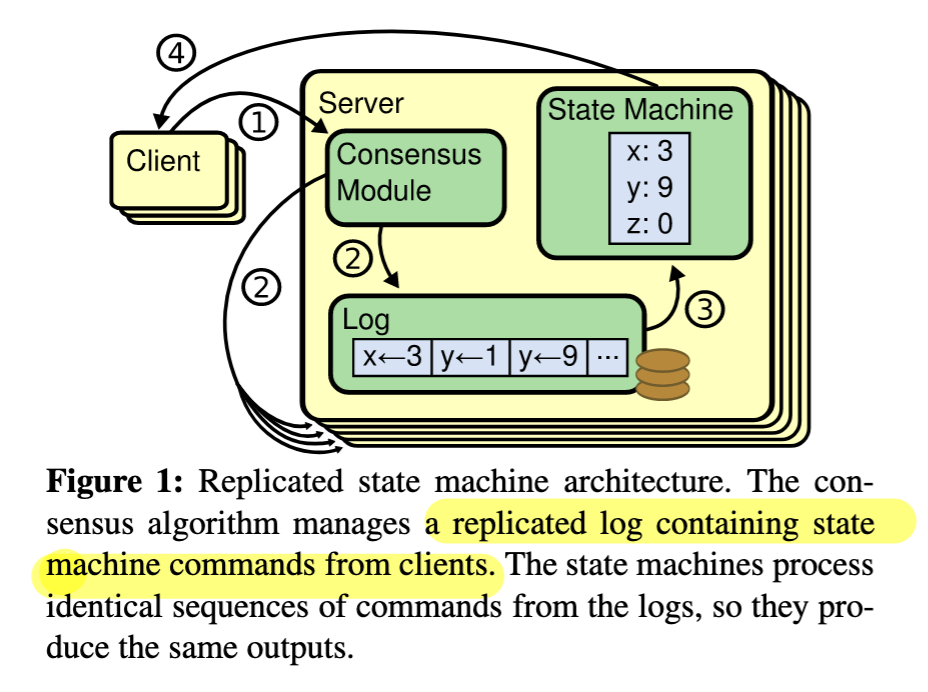
Raft’s basic architecture is:
- An odd-numbered (is this true?) cluster of machines, one of which is the leader. All nodes contain a replicated log and a state machine.
- Entries in the log contain potential changes to apply to the state machine. In addition, each log entry has a term and an index.
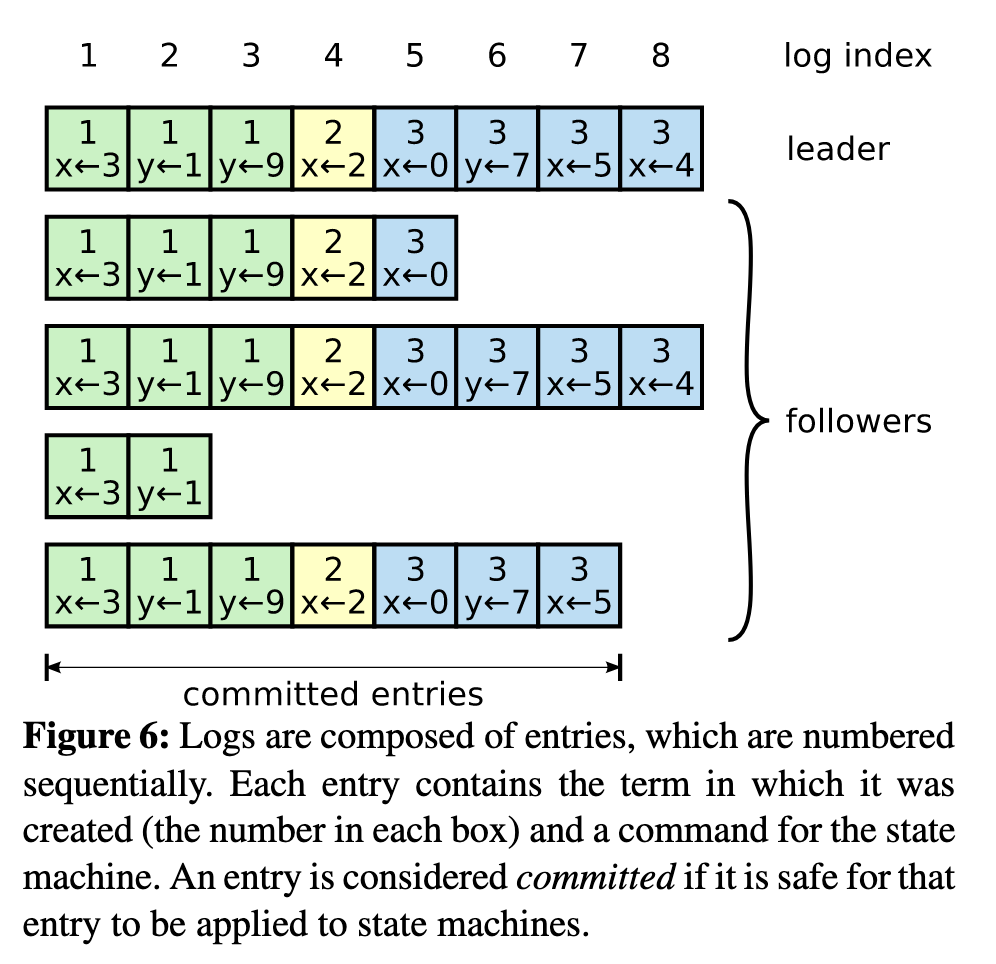
- As entries in the log are committed (replicated to a majority of the cluster), each node applies them to its local state machine.
-
Raft assumes non-Byzantine conditions, such as network delays/partitions, packet loss, duplication, and/or reordering.
-
Log entries only flow from the leader to followers.
-
Clock skew cannot affect Raft’s correctness: “faulty clocks and extreme message delays can, at worst, cause availability problems”
-
Paxos is hard to understand
We struggled with Paxos ourselves; we were not able to understand the complete protocol until after reading several simplified explanations and designing our own alter-native protocol, a process that took almost a year.
-
Paxos' primitive unit of consensus is a single entry, which is then melded into a sequential log, and this contributes to its complexity. Raft’s approach of using a log as the primitive unit makes a lot of things easier.
-
Examples of this?
As a result, practical systems bear little resemblance to Paxos. Each implementation begins with Paxos, discovers the difficulties in implementing it, and then develops a significantly different architecture.
-
One important reason understandability is important:
it must be possible to develop intuitions about the algorithm, so that system builders can make the extensions that are inevitable in real-world implementations.
-
All client requests are routed through the leader; does this preclude Raft from being used in multi
-
-region deployments?
Summary of the Raft Algorithm & Its Invariants


Election
-
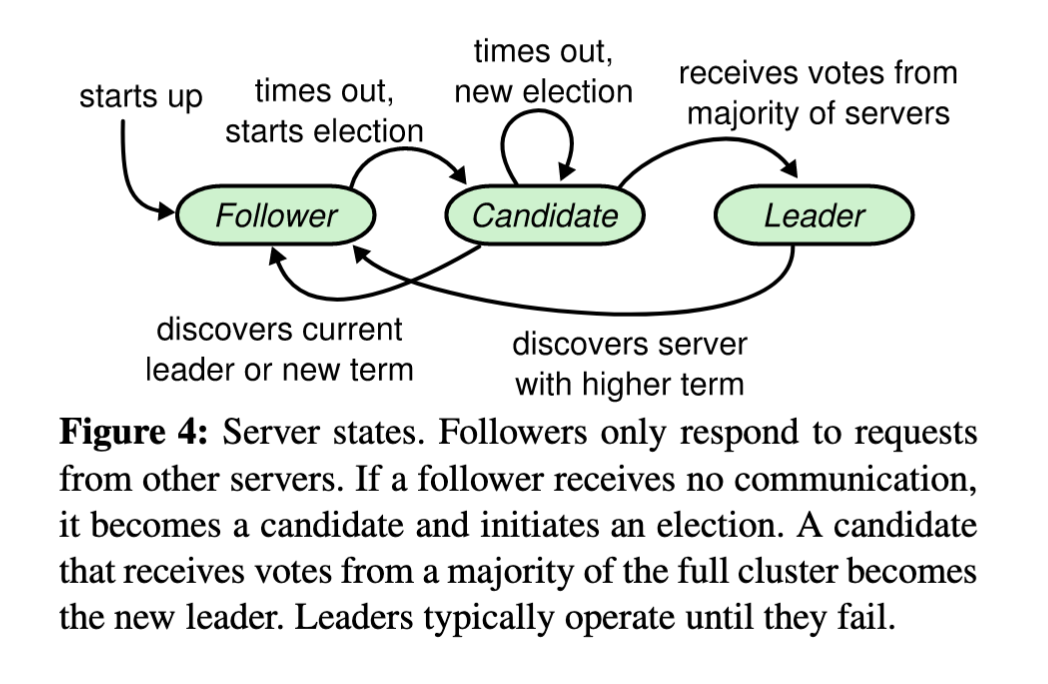
Every node can be in one of three states: candidate, follower, or leader. Raft divides time into terms; every term has exactly one leader. When a follower hasn’t received a heartbeat from the currently leader for a specified time interval (typically 100s of ms), it transitions to being a candidate and asks around for votes. If it receives votes from a majority of the cluster, it becomes the leader and starts a new term.
-
Every request between servers includes the term number; any request with a stale term number is rejected. Every request that times out is retried indefinitely.
Voting & Committing
- When the leader receives a client request to add a log entry, it immediately appends the log entry to its own log, and then attempts to replicate the entry to other machines. A log entry is considered committed if a majority of the cluster has appended it to their logs, at which point it can be applied to the state machines.
- This is a key property: for a node to become the leader, it needs to receive votes from a majority of the cluster. Similarly, for an entry to be committed, it needs to be replicated to a majority of the cluster. So it follows that during voting, at least one server voting for a given candidate contains all committed entries from the last term, and it will decline to vote if the candidate is not as up-to-date as itself. This ensures that every new leader contains all entries committed in previous terms.
Raft uses the voting process to prevent a candidate from winning an election unless its log contains all committed entries. A candidate must contact a majority of the cluster in order to be elected, which means that every committed entry must be present in at least one of those servers. If the candidate’s log is at least as up-to-date as any other log in that majority (where “up-to-date” is defined precisely below), then it will hold all the committed entries. The RequestVote RPC implements this restriction: the RPC includes information about the candidate’s log, and the voter denies its vote if its own log is more up-to-date than that of the candidate.

- Once a leader performs a commit in its current term, its entire log up to that point is committed. This is a bit tricky to understand, but essentially:
- When a leader is elected, it forces all followers to match its log (by discarding entries if necessary).
- Once it performs a commit in the current term, that ensures that only a node with that committed entry can be elected in the future, thus making all prior entries in the leader’s log committed as well.
Client Interaction
-
Clients can contact any node, and will be forwarded to the current leader. A split brain scenario is possible, so the leader waits for a majority (heartbeat for reads, commit for writes) before responding to the client.
-
If a leader crashes after committing the log entry but before responding to the client, the client will retry the command with a new leader, causing it to be executed a second time. The solution is for clients to assign unique serial numbers to every command. Then, the state machine tracks the latest serial number processed for each client, along with the associated response. If it receives a command whose serial number has already been executed, it responds immediately without re-executing the request.
Configuration Changes
-
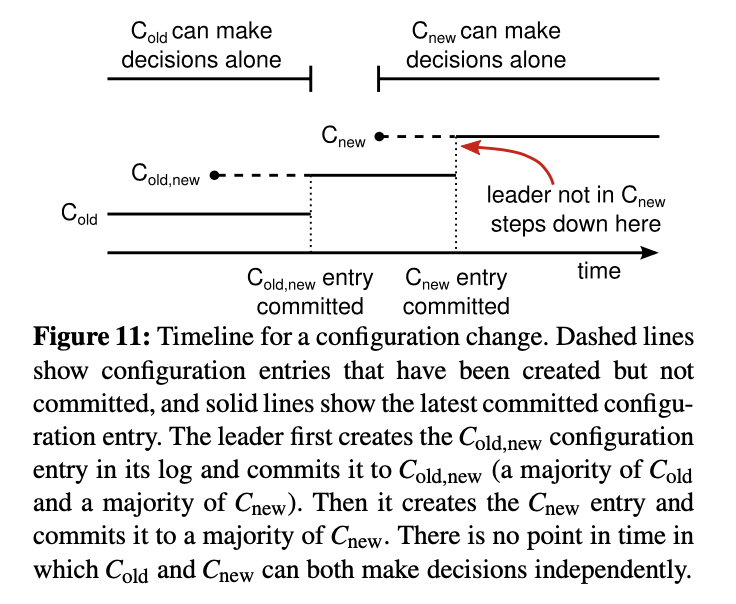
Raft handles configuration (the set of machines in the cluster) changes quite elegantly using joint consensus. If
Cnewis the new configuration andColdis the old configuration, andCold/newis the combination of both configurations:- The current configuration is
Cold. The leader creates theCold/newconfiguration in it’s logs, and waits until it is committed. Note that nodes start usingCold/newas the canonical configuration (for commits and voting) as soon as they apply the entry to their log, without waiting for a commit. 2.The current configuration isCold/new. At this point, a leader might be elected from either set of nodes. More importantly, voting and committing require a majority from bothColdandCnew(there might be some overlap). - Next, the leader attempts to commit
Cnew. Once that’s done,Cnewis the configuration, and voting/committing only requires a majority fromCnew.
- The current configuration is
-
New servers might take some time to catch up (during which time new commits are impossible), so an option exists to bring the servers on as non-voting members until they catch up, after which they can take part in majorities.
Compaction / Snapshots
- Raft uses snapshots for compaction. Snapshots of the state machine are taken at various intervals, by each node independently, which renders the log upto that point obsolete.
- If a leader has to send a follower log entries that it has already compacted, it now has to send its snapshot to the follower.
