Operating Systems - Three Easy Pieces
Introduction
-
Virtualization, concurrency, persistence
-
The OS takes a physical resource (such as the processor, or memory, or a disk) and transforms it into a more general, powerful, and easy-to-use virtual form of itself.
- Providing the illusion that each “program” has exclusive access to the CPU and memory
- Via processes and virtual memory
- Disk IO is somewhat different - the OS doesn’t pretend that each program has its own isolated disk (iOS?); the abstraction here is the filesystem instead of IO over raw disk blocks
-
OS priorities
- Perf: reduce the overhead of the OS itself
- Protection/isolation between processes
- Reliability: an OS crash is fatal
CPU Virtualization
-
Time-sharing via context switches to virtualize CPUs
-
Process state: (virtual) memory, registers, in-flight IO
- All this state must be saved/isolated to facilitate context switching
-
Process creation
- Lazily (mmap?) load code+data from disk→memory
- Allocate memory for stack and heap
- Fill the first stack frame with arguments (argc/argv)
- Set up initial file descriptors (stdin/stdout/stderr)
- Transfer CPU control to the address of the new process in memory
-
Process states: ready, running, blocked (IO, etc.), zombie (killed but not cleaned up)
-
OS data structures
- Process List: running/blocked processes + metadata (proc on xv6 and
task_structon Linux)
- Process List: running/blocked processes + metadata (proc on xv6 and
-
Process API Design
fork: creates a copy of the running process (and all that encompasses, incl. registers, memory, etc.), both the parent and child return fromforkwith different values. Parent → PID of child, Child → zero.wait: block until a child process exitsexec: overwrite the current running process with the named program
-
forkandexecbeing separate calls allows a parent process to run code between them. This allows for things like IO redirection and pipes. -
Spending some time reading man pages is a key step in the growth of a systems programmer
-
Need to balance perf (processes run as fast as if they were “bare-metal”) and control (a process can’t run forever)
-
Limited direct execution
- User mode / kernel mode so programs can perform privileged operations safely
trapinstruction used to switch to kernel mode, libc/etc. uses the hardware calling convention to pass args, etc.- Kernel sets up a trap table that tells the CPU where to jump when it sees a
trap/ system call, or other interrupt - Requires hardware support to disallow privileged instructions when running in user mode
- User code places a system call number in a specific (calling convention?) register
- Register state is stored in (and restored from) the kernel stack by the hardware
- How does the OS intervene when a process isn’t issuing any system calls?
- Interrupts! Requires hardware support
- The OS sets up an interrupt handler, the hardware jumps to that handler every time a timer interrupt fires (every X ms)
- Register state is stored onto the kernel stack (similar to a
trap) by the hardware - The OS scheduler then (possibly) performs a context switch by storing register state and restoring register state for the target process.
- The OS also maintains a kernel stack for each process; it now switches the stack pointer to the kernel stack for the target process.
- Hardware first saves register state onto the kernel stack when switching from user to kernel mode. The OS then saves the kernel stack and replaces it with the target process' kernel stack during the context switch.
return-from-trapnow runs the new process- To reiterate, two stores/restores
- Interrupt: User registers are stored in the kernel stack
- Context switch: Kernel registers are stored in memory, keyed by the previous process
-
in 1996 running Linux 1.3.37 on a 200-MHz P6 CPU, system calls took roughly 4 microseconds, and a context switch roughly 6 microseconds. Modern systems perform almost an order of magnitude better, with sub-microsecond results on systems with 2- or 3-GHz processors.
- User mode / kernel mode so programs can perform privileged operations safely
-
Scheduling
- Metrics
- Turnaround time: completed at - arrived at
- Response time: first scheduled at - arrived at
- Tradeoff between fairness (low response time) and performance (low turnaround time)
- IO
- Interleave jobs so the CPU isn’t idle when a job issues IO
- FIFO
- Performs well when all jobs run for the same duration
- Can make shorter jobs wait behind a longer job
- Shortest Job First (SJF)
- Non-preemptive, so this can make shorter jobs wait behind a longer job too
- Needs to know (or estimate) running time for every job
- Shortest Time-to-Completion First (STCF)
- SJF + preemption
- Preemption occurs when a new job enters the system
- “Provably optimal”
- Good for turnaround time, not good for response time
- Round Robin
- Preemption based on time slices
- Good for response time, not good for turnaround time
- Iterates over all available jobs, one movement per time slice
- Time slice duration is a multiple of the timer interrupt interval
- Smaller time slices are better for response time, but only up to a point, after which the context switching overhead dominates
- Context switching overheads: saving/restoring register state, but also losing state in CPU caches, TLBs, branch predictors, etc
- Multilevel Feedback Queue (MLFQ)
- Paper
- Optimize for turnaround time and response time
- Priority levels, round robin (time slices) at each individual priority level
- Sets priority based on behavior
- We want interactive processes to have high-priority and long-running batch processes to have lower priority
- New jobs enter the queue at the highest priority level, and jobs that use their entire time allotment are demoted a level
- Long-running jobs will eventually make it to the lowest priority level
- Shorter jobs will complete before that happens
- IO-intensive jobs will relinquish the CPU before their slice is complete, and will stay at the same priority level
- The time allotment is counted across time slices
- To avoid processes gaming the system by giving up the CPU just before their slice is up.
- So instead the scheduler remembers how much a process has used the CPU on a given priority level, and makes the demotion decision based on this total time.
- We can’t know how long a job will run, so assume every job is a short job to start with
- In addition, periodically (how often?) boost running jobs to the topmost queue
- Prevents lower priority levels from starving out
- Allows for changes in a process' workload to be noticed
- Summary of MLFQ rules
-
- Time slices can vary across priority levels, higher priority == smaller slices
- Some schedulers reserve the highest priority levels for the OS/kernel itself
niceto adjust the priority of a job, similar tomadvise/etc.- Does Linux use an MLFQ, and are these parameters user-configurable if so?
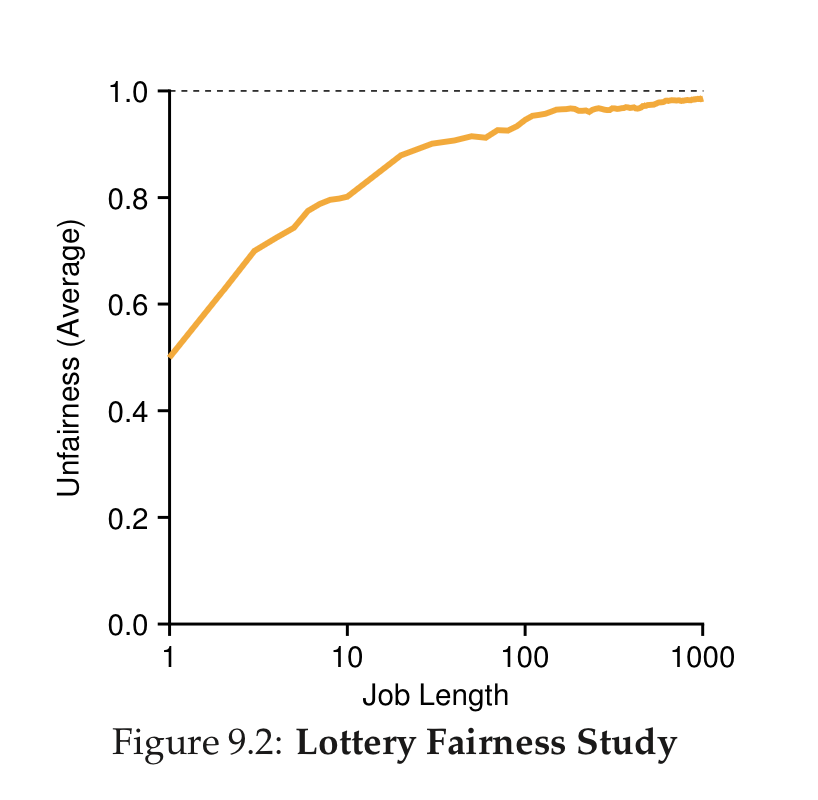
- Proportional Share / Lottery Scheduling
- Paper
- Each process gets a certain number of tickets
- Every time slice, pick a process to run by making a random choice weighted by ticket count (processes with more tickets are more likely to be chosen)
- Unfairness can be a problem for short-lived jobs, but longer-lived jobs are more likely to be scheduled according to the proportion of tickets they hold
-
- Stride scheduling is a variant that achieves exact proportions by being deterministic, but requires global state
- Multiprocessor Scheduling
- Difficult because of cache coherence issues
- If CPU A runs a process and performs a write that makes it to L1 but not further, and then the process is rescheduled onto CPU B, that write is lost
- This class of issue is typically solved in hardware, the kernel only really needs to worry about locking/etc.
- Affinity: scheduling a process onto a different core leaves it with a cold TLB and caches, prefer a single core if possible
- Put jobs in a single (all cores pick from the same queue) or multiple-queues (each core has its own queue, migrate jobs between queues occasionally to prevent imbalance) and usem to dispatch between cores
- Once a core has been picked, does a more advanced algorithm like MLFQ/etc. kick in?
- Metrics

Memory Virtualization
-
Every address generated by a user program is a virtual address
-
Can’t flush/restore all of main memory on every context switch, too expensive
-
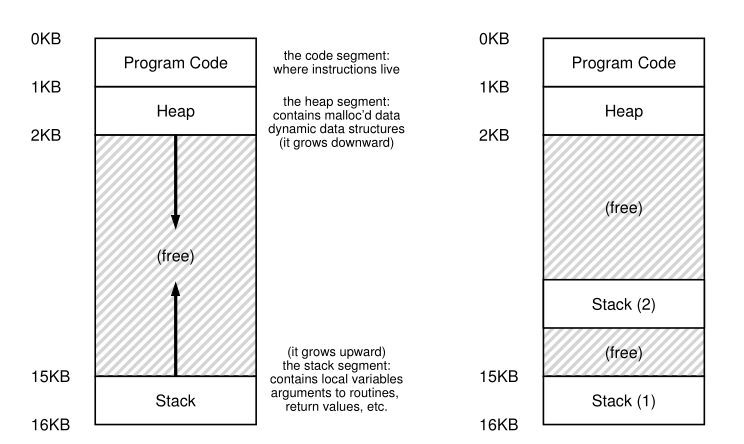
Typical layout, heap grows downward, stack grows upwards
-
-
Can the contents of freed memory become visible in a different process' address space?
-
Virtual→physical translation happens on the hardware directly, using translation tables set up by the kernel
-
Assumptions
- Virtual address space is smaller than main memory
- All processes have identically sized address spaces
- The virtual address space is placed contiguously in main memory
-
Base-and-bounds relocation
- Hardware support (MMU): two registers, base and bound
- The OS sets the base register to a physical offset
- The hardware then translates each virtual (userspace) address to a physical address by adding the base value to it
- The OS sets the bounds register to the size of the virtual address space (or the physical address marking the end of the address space, in some cases)
- The virtual address is invalid if larger than the bound
- In this example, base is 32KB and the bound is 16KB
-
- The OS updates the base & bounds registers on every context switch
- The entire virtual address space can be relocated to a different physical area while the process isn’t running
- Cons: free space in the virtual address space is wasted, a much bigger problem for large address spaces (32-bit == 4GB)
-
OS uses a free list to find free memory to allocate
- Put memory back into the free list when a process terminates
-
Segmentation
- The code section, heap, and stack are each individually placed into phyiscal memory, each with a base/bounds register pair
- Each segment is bounded by used memory, not total available (virtual) memory
- Segmentation fault: invalid/out-of-bounds memory access on a machine with segmented VM
- Translation is a bit different. You don’t just add the base to the virtual address, but you first translate the virtual address to an offset from the start of the current segment, and then add that to the base, because the base is per-segment.
- As an example, a virtual address in the heap section will have 4096 subtracted from it (start of heap) before adding the base in
-
- The stack grows backwards, so it’s base is set to the end of its virtual address space, and the translation layer uses a flag to keep track of which segments grow backwards. These segments use different translation logic to compute a negative offset.
- How does the translation layer know which segment is being translated?
- Explicit: Use the high 2 bits of the virtual address to select the segment, and the remaining bits as an offset into the segment. The base address is only added to the offset
- Implicit: the hardware determines the segment by noticing how the address was formed. If, for example, the address was generated from the program counter (i.e., it was an instruction fetch), then the address is within the code segment; if the address is based off of the stack or base pointer, it must be in the stack segment; any other address must be in the heap.
- Cons: fragmentation in physical memory can cause allocations to fail even if enough memory exists in aggregate. Many allocation strategies exist to minimize fragmentation, but no silver bullet.
-
Sharing
- Segments that are readonly (or read-execute) can be shared across processes
- Protection bits to track whether a segment is writable or not
-
Memory Allocation
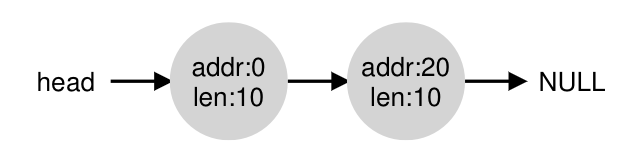
- Free list to track regions of free space
-
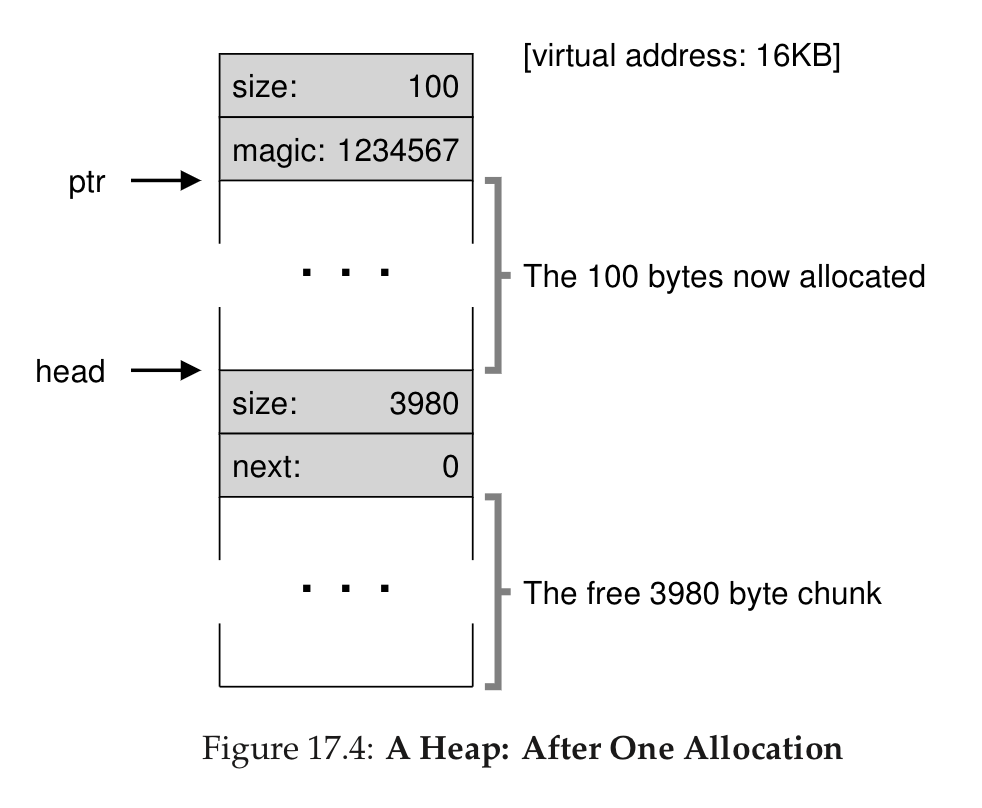
- Allocate a piece of memory smaller than free list items by splitting a free list item in two
- When memory is freed, coalesce with existing free list items that line up exactly, if any
free()takes a pointer to the memory in question but not the length/size of the memory to be freed, so this needs to be tracked by the allocator- Allocators store this sort of thing in a header block that immediately precedes each block of memory that’s handed out.
malloc(size)allocates a regionsize + <header_size>bytes large. freegets to the header withptr - sizeof(header)
- Free list to track regions of free space
-
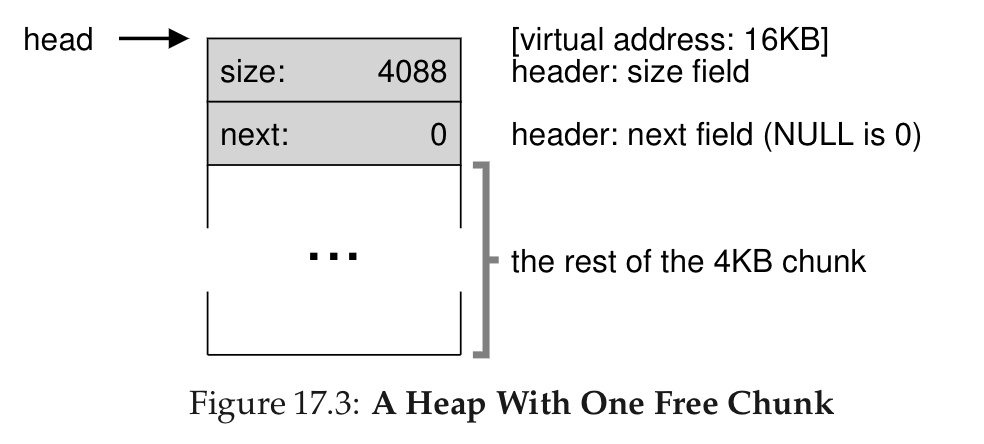
Where is the free list located?
- Can’t
mallocinside the allocator impl - Need to use the chunk of memory that the allocator is managing
- Use a header for each free chunk of memory instead
- When an allocation is requested, find a free chunk and split it
-
- When
freeing a chunk of memory, don’t touch the memory itself, just modify the header so that chunk is spliced back into the free list
- Can’t
-
Allocators run in userspace, and request memory from the OS using
sbrk/etc. -
Segregated lists
- Multiple free lists, one or many that only store chunks of a fixed size, matching frequently-allocated objects, and a more general list that accommodates more variable requests
- The Solaris slab allocator does this for kernel structures like inodes and locks, but also keeps these structures in a pre-initialized state in the free list(s)
-
Advanced allocators use more complex data structures than lists: binary trees, splay trees
-
The large chunk(s) of memory that the allocator manages is sometimes called an arena
-
Paging
- Split virtual memory into fixed-size blocks instead: pages
- Also split physical memory into fixed-size blocks: page frames
- Per-process page table to translate from virtual→physical address
- Higher bits of the virtual address are a page number, lower bits are the offset within the page. 12 offset bits for 4KB pages.
- The offset isn’t translated, only the page number needs to be looked up in the page table
- Page tables can grow very large, a 32-bit address space with 4KB pages has (at most) ~1M pages, and for a 64-bit address space that balloons to ~4 quadrillion pages
-
Page table
- Simplest representation is an array, index by page number to get the phyiscal address. Could be problematic for sparse page tables.
- Metadata
- Valid: a translation exists for this virtual address (isn’t this implicitly known via array membership?)
- Protection bits: read/write/execute perms
- Dirty: page modified but not flushed
-

- PFN: page frame number
-
-
TLB
-
The extra memory access to look things up in a page table is expensive
-
TLB: hardware cache of virtual→physical translations, part of the MMU
-
Benefits from spatial locality: iterating an array only requires going to the page table once per page instead of once per array element
-
Benefits from temporal locality: accessing the same memory multiple times
-
If you want a fast cache, it has to be small, as issues like the speed-of-light and other physical constraints become relevant.
-
x86 handles TLB misses in hardware; the CPU walks the page table directly and caches the result
- Page table address is put in the CR3 register
- Hardware defines the page table structure/format
-
RISC architectures raise an exception and have the OS handle TLB misses
- The OS TLB miss handler has to be careful not to itself cause a TLB miss (infinite loop)
-
Typically only stores 32, 64, or 128 entries
-
Has a valid bit with different semantics
- TLB valid: this is a valid cache of a single page table entry
- PTE valid: this points to a physical page allocated to the process
-
Is the TLB flushed on every context-switch?
- That’s one strategy but can be expensive
- Use an address space ID instead to disambiguate different virtual address spaces
-
Eviction policies: random, LRU, etc?
-
It’s normally equally expensive to access any portion of RAM, but the VM+TLB skews this, so some memory accesses are far more expensive than others
-
Testing for TLB size
-
Allocate an array that spans X pages, and write to the array at least once on every page. Do this a few million times and find an average duration.
-
Once X pages stop being able to fit in the TLB the duration should have a marked jump
-
In this case the TLB probably holds 512 PTEs
❯ for i in 2 4 8 16 32 64 128 256 512 1024 2048; do ./out $i 40000000; done 2 40000000 2.799437ms 4 40000000 2.292656ms 8 40000000 2.276975ms 16 40000000 2.274916ms 32 40000000 2.271962ms 64 40000000 5.752445ms 128 40000000 4.545001ms 256 40000000 3.842841ms 512 40000000 3.640350ms 1024 40000000 7.840927ms 2048 40000000 8.659336ms -
Other considerations
- Disable compiler optimizations
- Pin to a single core (using
sched_setaffinity) so the process isn’t scheduled to a different core while running
-
-
-
Page table size
- Array based page tables can be too large, especially given that they’re per-process and need to be fully allocated even on sparse address spaces
- Larger page sizes == smaller page tables
- For a 32-bit address space and a 4-byte PTE, using 4KB pages means that:
- We reserve 12 bits for the offset
- And the remaining 20 bits for the page number
- So the max page count is 1048576
- And the page table uses 4MB
- If we use 16KB pages instead:
- We reserve 14 bits for the offset
- And the remaining 18 bits for the page number
- So the max page count is 262144
- And the page table uses 1MB
- Cons: internal fragmentation; space is wasted within allocated pages
- For a 32-bit address space and a 4-byte PTE, using 4KB pages means that:
- Some architectures support multiple page sizes, some applications (databases especially) request large pages for their data to reduce the probability of TLB misses
-
Multi-level page table
- Two levels
-
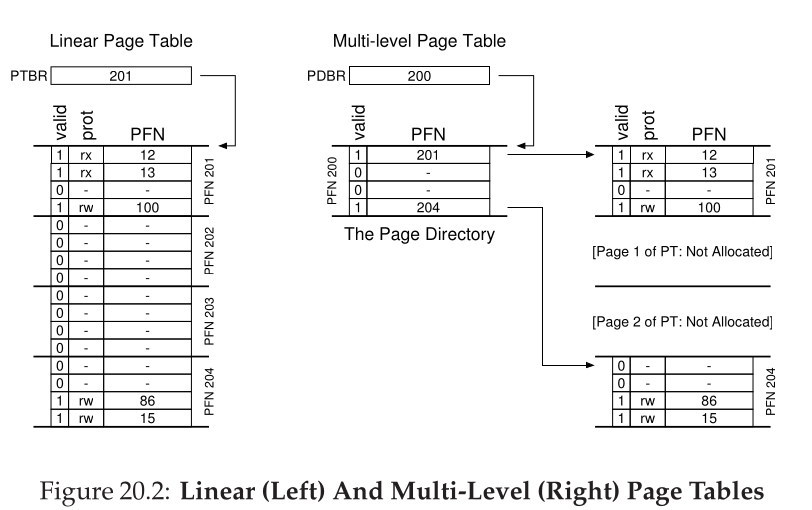
- Split the linear/array-based page table itself up into pages
- Any pages that are entirely invalid don’t have to be allocated
- Use a page directory to look up pages of the page table
- Page directory entries point to physical addresses of page table pages, such an entry is marked valid if at least one of the PTEs in the page table page is valid (and that page table page is therefore allocated)
- Two memory accesses now required (if TLB miss), but requires far less space
-
- The page directory must be fully allocated though, if it gets too big, split that into multiple pages and set up a second directory for it, creating a multi-level page table
- Two levels
-
Inverted page tables
- Instead of mapping virtual->physical addresses, map physical->virtual addresses, with a record of which process is using a given physical page.
- Looking up an entry requires either a full scan or a hash-map/etc. associated with it
- But this only needs to store as many PTEs as there are physical pages (not per-process)
-
Address spaces larger than main memory
- Reserved on-disk space for heap pages: swap
- Not exclusive, pages for the code section are backed by the regular filesystem, for examplea
- Extra flag in every PTE to determine if the page is in memory or not: present bit
- Accessing a page not in physical memory: page fault, control is transferred to the OS to handle it (page fault handler)
- During a page fault the process is paused/asleep while the page is fetched from disk
- Control flow on a TLB miss
-

- TLB miss -> page table -> PTE has
presentunset -> disk I/O to load page into memory -> update PTE - TLB miss -> page table -> PTE has
presentset -> update PTE
-
-

- The OS doesn’t wait until memory is full before evicting to disk
- Low & high watermark
- If the number of free pages in memory is lower than the low watermark
- Evict pages to disk until the number == the high watermark
- This allows batching evictions for more efficient IO
- Main memory contains a subset of all pages, and so is like a cache (page cache)
-
Is access to the page table cached in L1/2/3 as well as the TLB?
-
Recall, importantly (and amazingly!), that these actions all take place transparently to the process. As far as the process is concerned, it is just accessing its own private, contiguous virtual memory. Behind the scenes, pages are placed in arbitrary (non-contiguous) locations in physical memory, and sometimes they are not even present in memory, requiring a fetch from disk. While we hope that in the common case a memory access is fast, in some cases it will take multiple disk operations to service it; something as simple as performing a single instruction can, in the worst case, take many milliseconds to complete.
- Page cache eviction
-
Disk IO is so expensive that even a small change in cache hit rate means a disproportionately large slowdown
-
(Theoretical) optimal policy: evict the page that will be needed the furthest in the future
- Useful to figure out how close an actually-implementable eviction policy gets to the idea
-
FIFO & random eviction: not very efficient
-
LRU: better in some cases
-
Workload testing (100 pages, 10k accesses, cache size is varied) How much access data is the LRU caching machinery allowed to store?
- No-locality
- When the access pattern has no locality (spatial or temporal), it doesn’t really matter what eviction policy you use
-
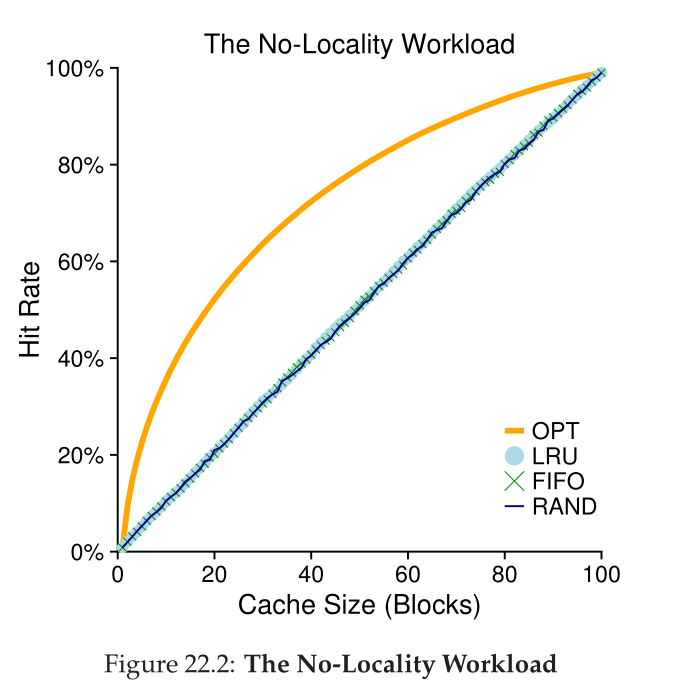
- 80-20
- 80% of requests are made to 20% of all pages (hot pages)
-
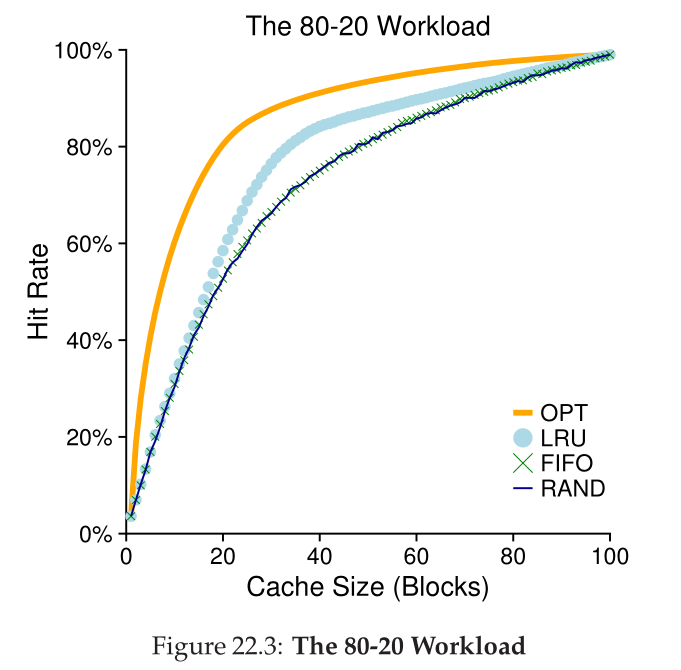
- Sequential
- Refer to 50 pages sequentially, and in a loop
-
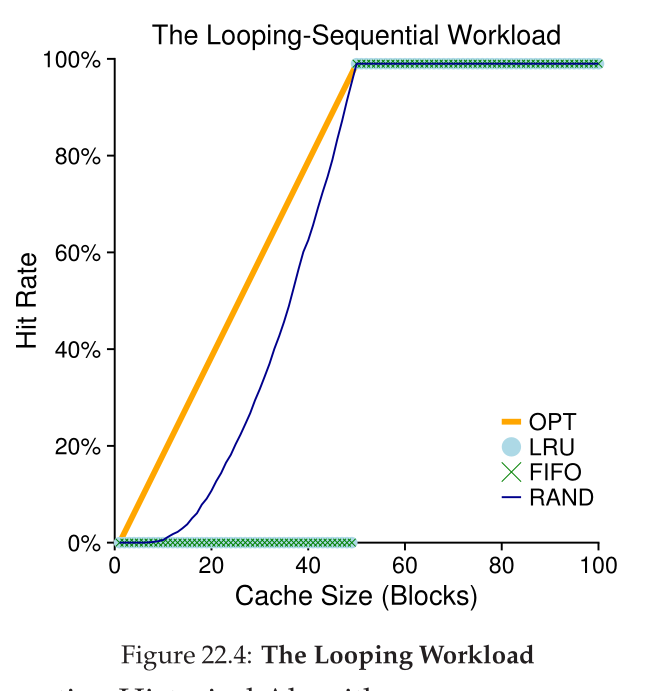
- Pathological LRU performance until the entire set of pages fits in memory
- No-locality
-
LRU is hard to implement because tracking recency data adds extra overhead to every memory reference, even on a cache hit
-
Approximate LRU instead
- One “use bit” per page
- Hardware sets the use bit when the page is referenced (read or write)
- The OS uses some strategy to periodically clear use bits and perform eviction
- One such strategy is the clock algorithm:
*
How does the OS employ the use bit to approximate LRU? Well, there could be a lot of ways, but with the clock algorithm [C69], one simple approach was suggested. Imagine all the pages of the system arranged in a circular list. A clock hand points to some particular page to begin with (it doesn’t really matter which). When a replacement must occur, the OS checks if the currently-pointed to page P has a use bit of 1 or 0. If 1, this implies that page P was recently used and thus is not a good candidate for replacement. Thus, the clock hand is incremented to the next page P + 1, and the use bit for P set to 0 (cleared). The algorithm continues until it finds a use bit that is set to 0, implying this page has not been recently used (or, in the worst case, that all pages have been and that we have now searched through the entire set of pages, clearing all the bits).
-
Pages that have been dirtied must be written to disk as part of eviction
- Eviction strategy should prefer clean pages to avoid this overhead
-
- Page cache loading
- Demand paging: load pages into the cache when accessed for the first time
- Prefetching: attempt to guess which pages might be accessed soon
- Thrashing: the system is constantly paging because its needs are larger than main memory can provide
- Refuse to schedule a few culprit processes to give others a chance to recover
- OOM killer
-
in many cases the importance of said algorithms has decreased, as the discrepancy between memory-access and disk-access times has increased. Because paging to disk is so expensive, the cost of frequent paging is prohibitive. Thus, the best solution to excessive paging is often a simple (if intellectually dissatisfying) one: buy more memory.
- Page cache eviction
-
Case study: VAX/VMS
- 32-bit address space, 512-byte pages
- Address space is segmented into two segments (P0 & P1), top two bits of the address pick a segment
- Each segment’s page table is bounded, so the first ends where the heap ends and the second ends where the stack ends
- All user page tables live in kernel virtual memory, so the system checks the kernel page table to find the user page table
- Address space
- More complex than we’ve seen so far
-
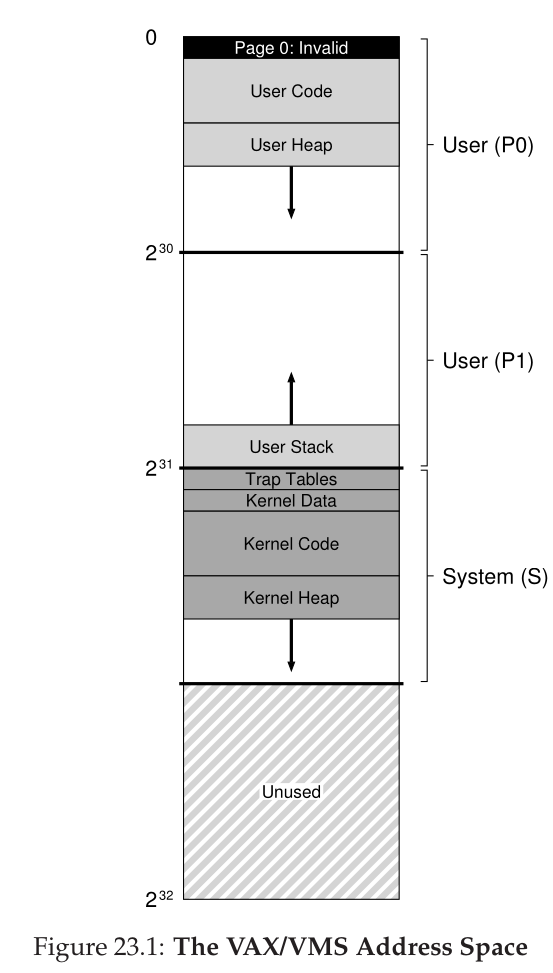
- The code section doesn’t start at page 0 because page 0 is what’s looked up during a NULL pointer dereference, so page 0 is permanently marked invalid
- Kernel memory is mapped onto every process' address space, to make copying from user memory to kernel memory (and back again) easier
- Protection bits to ensure that user code can’t access kernel mappings without being in kernel mode
- Segmented FIFO
- LRU/etc. is vulnerable to hogging and isn’t designed to be fair across processes, just to reduce the miss rate
- Instead set a limit for the number of pages each process can keep in memory: resident set size
- Per-process FIFO, with two global second-chance queues
- Demand zeroing
- Add a new page to the virtual address space my adding a new empty PTE marked inaccessible
- If the process then accesses that PTE, trap to the OS, which then finds an actual free page, zeroes it, and slots it in
- Copy on write
- If a page needs to be copied across two address spaces
- Use the same physical page in both places, but set metadata to show that this is a CoW page
- If both processes read from the page but don’t write, no actual copying is needed
- If a process writes to the page, trap to the OS, which allocates a new page, performs the copy, and slots it in
- Important on Linux because
fork()creates a copy of the process' entire address space, which is then possibly replaced ifexec()is called


Concurrency
- The thread abstraction: multiple flows of control that share the same address space
- But separate program counters, registers
- And a regular context switch is required to switch between them, using a “thread control block” to save thread state instead of a “process control block”
- Each thread needs its own stack
-
- Single thread on the left, two threads on the right
-
pthread_createandpthread_join, thread creation appears to use the clone syscall
-

- Locks
pthread_mutex_lockandpthread_mutex_unlock- Design considerations: mutual exclusion, fairness, perf
- Can switch off interrupts to prevent a critical section from being interrupted
- But this precludes preemption and doesn’t really work when parallelism > 1
- The OS might use this strategy internally
- “interrupt masking”
- Hardware support
- The simplest primitive is a test-and-set swap instruction (
xchgon x86)-
The text refers to this as a “test-and-set” instruction, but I don’t see a test happening 🤔
-

-
Unless the only valid values for
int neware 0/1? -
Apparently the only valid value is 1, and test-and-set isn’t the same thing as CAS *
The test-and-set instruction is an instruction used to write (set) 1 to a memory location and return its old value as a single atomic. The caller can then “test” the result to see if the state was changed by the call.
-
This is sufficient to build a spinlock, which needs a preemptive scheduler to work well
-
- CAS
- Load-linked/store-conditional (MIPS)
- Load-linked is a simple load
- Store-conditional only performs the store if an intermediate load hasn’t happened since the last load-linked
- Fetch-and-add (atomic increment)
- This enables the “ticket and turn” locking mechanism
- A call to
lockincrements an atomic counter and returns its value as the ticket - An internal counter is incremented, and when that counter matches a ticket value, it is that thread’s turn
- Ensures fairness; every lock is scheduled to be unlocked
- The simplest primitive is a test-and-set swap instruction (
- Avoid spinning
- Yield control back to the OSs when a test-and-set/etc. fails
- Better than spinning but still costly because of context-switch overheads
- Also the OS scheduler may starve some threads and only let other threads make progress
parkandunpark(Solaris)- These functions put the current thread to sleep and allow wakeups by ID
- Build a lock using park/unpark with a flag (0: lock not held, 1: lock held) and a queue
- A spinlock is used to guard access to the flag and queue, but the lock doesn’t spin for the entire duration of the critical section
- While locking, set flag to 1 if currently 0 (lock was available) or add the current thread to the queue and park it otherwise
- While unlocking, unpark the thread at the front of the queue if one exists, otherwise set flag to 0 (lock is available)
futex(Linux, “fast userspace mutex”)- Every futex has a physical memory location attached to it
futex_wait: puts the calling thread to sleep and enqueues it if an equality check passes against the memory location, returns immediately otherwisefutex_wake: wakes up a thread from the queue- NPTL (glibc’s pthreads impl) uses futexes to build a mutex
- The futex uses a single signed 32-bit integer with the high bit representing whether the lock is held or not (1: held, 0: free)
- So a negative value for the number implies that the lock is held
- Lock by checking the lock bit, if free, set to 1 and acquire immediately
- If not, increment the number, add to the futex queue and wait, once awoken, check the lock bit again (and repeat)
- Unlock by checking if the lower 31 bits == 0, if so, no other waiters exist. If not, wake one of the waiters up
- Two-phase locks: spin for a bit, and only sleep if that fails
- Use to have one thread sleep (busily?) while waiting for another thread
- Lock-based concurrent data structures
- Sloppy counters
- Every CPU has an associated counter, plus one global counter
- Increments happen on CPU-local counters, reads happen on the global counter
- Local counters are periodically flushed to the global counter (requires locking the global counter)
- Sloppiness: how often the flush operation occurs, tradeoff between consistency/perf
- Sloppy counters
- Condition variables
pthread_cond_waitandpthread_cond_signal- wait: go to sleep
- signal: wake up one of the waiters
- Isn’t this just a tiny amount of sugar over futexes?
- Use to implement a buffer shared between producers and consumers
- Two conditions, empty and full
- Producers wait on empty and signal on full
- Consumers wait on full and signal on empty
- Semaphores
- Hold a single value, allow waiting and posting
- Wait: Decrement value, wait if negative
- Post: Increment value, wake a waiting thread if one exists
- Use to implement a lock
- Start with value 1
- Wait to lock, post to unlock
- Event-based concurrency
- Concurrency without threads
- Event loop: wait for events, process events, repeat
- Explicit control over scheduling by controlling the events that are fired
- Single-threaded, non-blocking/async IO
- select/poll allow a program to be notified when FDs are available to be read from, written to, or have an error condition set
- Cons
- Can’t take advantage of multiple cores easily
- The event loop necessarily blocks during a page fault, which can be problematic
- Concurrency bugs
-

Persistence
- Structure of a typical system
-
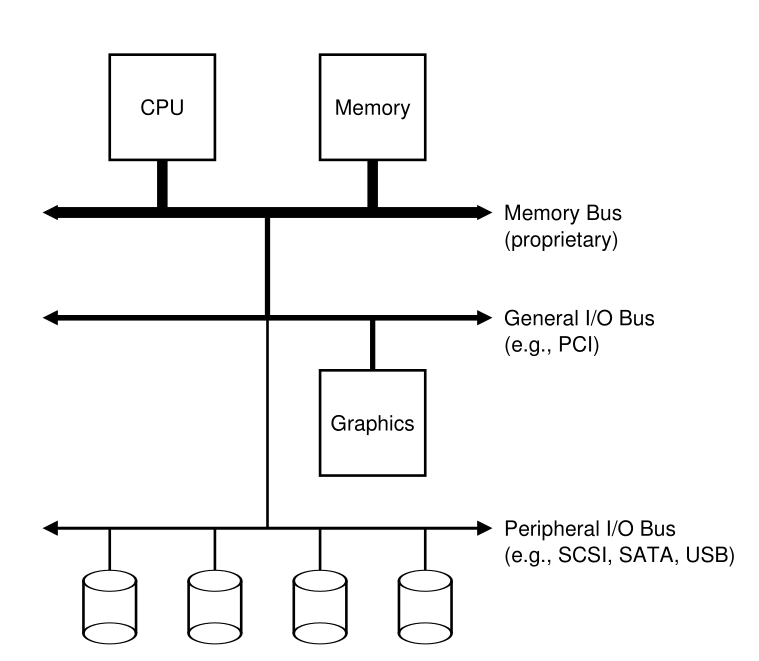
- Hierarchy of buses, each slower than the last
-
- A generic device
-
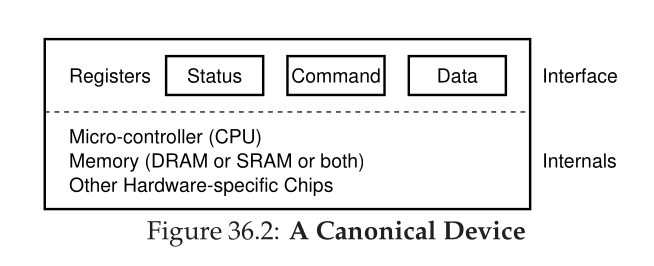
- Three registers: check the device status, pass/receive data, and issue commands
-
- How to be notified when the device is done?
- Programmed IO (PIO): busy polling
- Interrupts
- Slower than polling if the device is typically always ready at the first poll
- Not a good fit for fast devices
- Can overload and lock up a system if the amount of time spent responding to interrupts goes to 100%
- Coalescing: devices send interrupts for batches events
- DMA
- Even with interrupts, the CPU is busy while data is being copied from/to the IO device
- Direct memory access instead, a specialized device that can perform this task, freeing up the CPU
- Device drivers
- Code specific to each device, abstracted away from higher levels of the OS
- 70% of Linux code is device drivers
- Example IDE device driver
-

- The hardware (CPU?) makes the device’s registers available at the specified memory locations: memory-mapped IO
-
- Hard disk drives
-
Sectors are 512-byte blocks
-
Multi-sector writes are possible, but drives only guarantee atomicity at the sector level
-
Sequential reads are faster, but also reading two nearby sectors is faster than reading two sectors that are far apart
-
Do filesystems reliably handle the corruption edge cases here?
-
Magnetic charges are induced onto platters to store data persistently
-
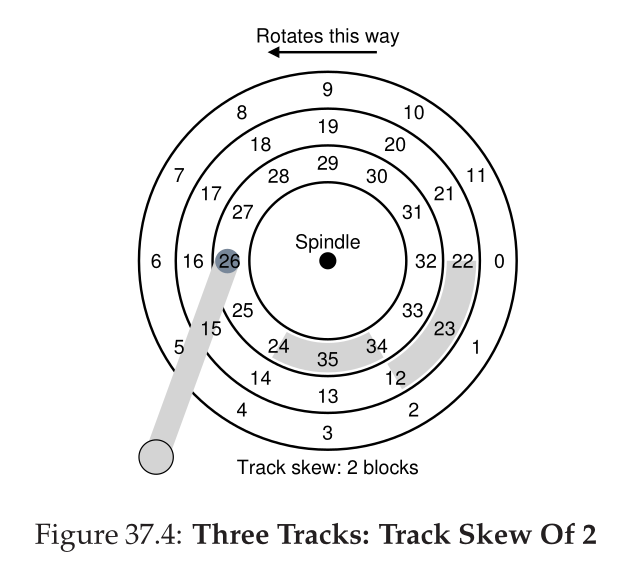
Data is encoded on each surface in concentric circles of sectors; we call one such concentric circle a track. A single surface contains many thousands and thousands of tracks, tightly packed together, with hundreds of tracks fitting into the width of a human hair.
-
The disk head reads data from the spinning platter under it, waiting until the sector rotates to the right place
-
At the same time, the disk arm - which the head is attached to - moves to the right track, this is a seek
-
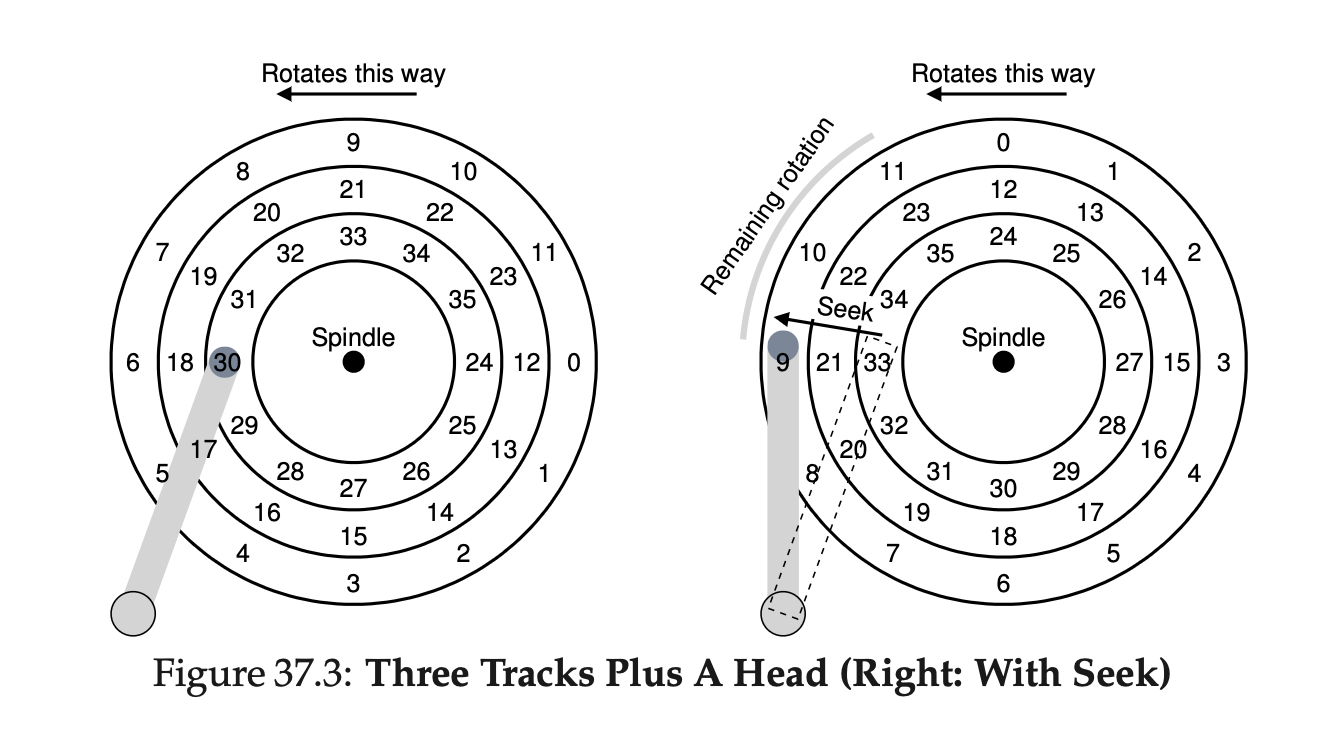
-
Tracks are skewed to accommodate seek time for sequential reads that cross a track boundary
-
-
8-16MB cache - the HDD can make decisions about prefetching, lazy persistence, etc.
-
IO time = time to rotate + time to seek + time to transfer
-
Disk scheduler
- The OS (is this part of the device driver or higher up?) schedules IO jobs so as to maximize throughput
- Strategies
- Shortest seek time / nearest block first: pick jobs on the current track before jobs on the next track over, etc. Jobs further out could starve
- Elevator: iterate over tracks, any requests for previous tracks have to wait until the next go-round. Rotation is ignored and could make things slower
- Shortest positioning time first: use seek time and rotation time to make an informed decision each time. The OS doesn’t have access to rotation data, so this is typically implemented in firmware.
-
In modern systems, disks can accommodate multiple outstanding requests, and have sophisticated internal schedulers themselves (which can implement SPTF accurately; inside the disk controller, all relevant details are available, including exact head position). Thus, the OS scheduler usually picks what it thinks the best few requests are (say 16) and issues them all to disk; the disk then uses its internal knowledge of head position and detailed track layout information to service said requests in the best possible (SPTF) order.
-
The OS can (and should) merge IO requests to adjacent or nearby sectors
-
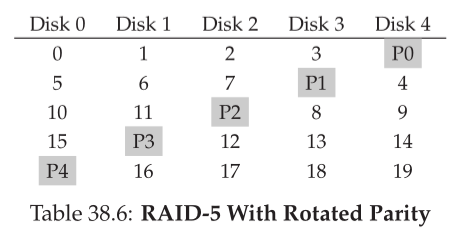
- RAID
- Hardware RAID is transparent to the levels above the device driver, and looks just like a regular (but larger and/or safer) disk, presenting a sequence of blocks/sectors
- RAID 0
- Stripe blocks/sectors across disks to maximize throughput, but also to combine multiple disks into a single one
-

- Possibly write multiple blocks to a disk before moving to the next: chunking
- Is the RAID controller itself a bottleneck here?
- RAID 1
- Blocks/sectors are placed in more than one disk, and they’re also striped as in RAID 0
-

- Writes go to more than one disk; firmware uses a WAL (!) to apply writes consistently
- RAID 4
- Store “parity” info on a disk, allows the loss of up to two disks
- XOR is a good parity function. Every stripe is XORed, and any one block in the stripe can be recovered with the others + the XOR result
-

- The parity disk becomes a bottleneck for a workload with many small writes
- RAID 5
- Parity is striped across drives
-
- Files & directories
- Each file/directory is identified by its inode number (unique per filesystem)
- A file descriptor is a private per-process identifier for a file
- Writes are typically buffered at the OS level, use
fsync()to flush to disk- For file creation the directory containing the file needs to be fsynced as well
statorfstatfor file metadataunlinkto delete filesopendir/reaaddir/closedirto read directory streams- Hard links: multiple entries in the filesystem that point to the same file (same inode)
Filesystem entry ---(via inode)---> metadata ----(via block/sector ID)---> disk- Deleting a file uses
unlinkto just remove the filesystem entry - If the reference count hits zero, the inode+metadata is removed too
- Hard links to directories are not allowed (this may make cycles possible)
- Ditto for links across volumes/filesystems
- Soft links
- Are a separate file that point to the original
- Contain the pathname of the target file, sized accordingly
- Dangling references are possible
- Links across volumes/etc or to directories work fine
- Filesystems
-
Divide the disk into blocks (block size), presumably different from the actual on-disk sector size
-
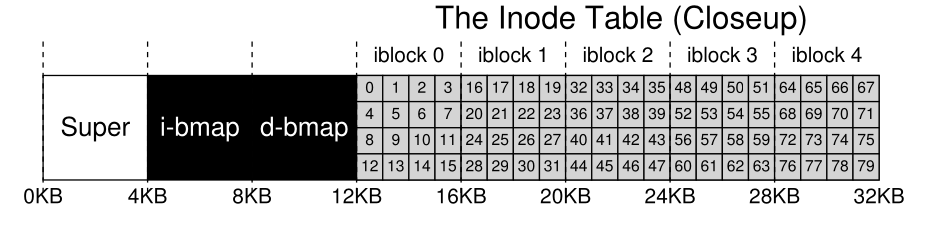
Reserve (most of the) space for user data, some space for inode→block metadata (inode table)
-
Inode capacity is reserved at filesystem creation time,
df -ito see free%❯ df -i Filesystem Inodes IUsed IFree IUse% Mounted on dev 4098958 676 4098282 1% /dev run 4101581 1258 4100323 1% /run /dev/nvme0n1p2 15253504 1914567 13338937 13% / tmpfs 4101581 139 4101442 1% /dev/shm tmpfs 1048576 95 1048481 1% /tmp -
Use two bitmaps to determine if a given inode slot/data slot is free, not required for addressing (reads)
-
Superblock that contains more global metadata (filesystem type, on-disk layout, inode count), loaded into memory when the disk is mounted
-
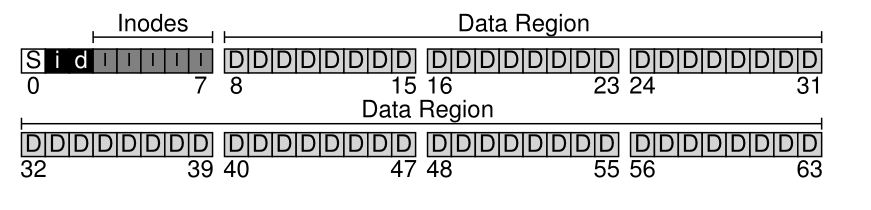
- S: superblock, i: inode bitmap, d: data bitmap, i: inodes, D: data
-
The on-disk location of an inode is deterministic relative to the inode number:
-
-
Disks are not byte-addressable, so an entire sector must be retrieved for an inode lookup
-
Inodes point to data blocks in (one of) two ways
- Pointers
- Directly point to a data block’s location.
- This doesn’t work for files that are larger than a single data block.
- Use a multi-level pointer tree (pointer to a block full of pointers, and so on) to individually address each block that represents the file
- “Indirect pointers”
- This allows storing a file without requiring contiguous storage, but uses a lot of metadata
- Extents
- Point to the start of the file + an extent (length)
- Cheap for metadata, but requires that contiguous storage is available
- ext2/3 use pointers, ext4 uses extents
- Pointers
-
Directories contain (filename, inode) pairs, inodes don’t contain filename info, including entries for
.and.. -
How does the filesystem handle concurrency for both bitmaps? (multiple files getting the same inode, etc.)
-
open()traverses each entry of the pathname, looking up the inode for each directory- It then looks up the data block for each of those inodes to find subdirs
- Caching to make this not slow
- does this use a specialized cache or just the page cache? page cache, sounds like
-
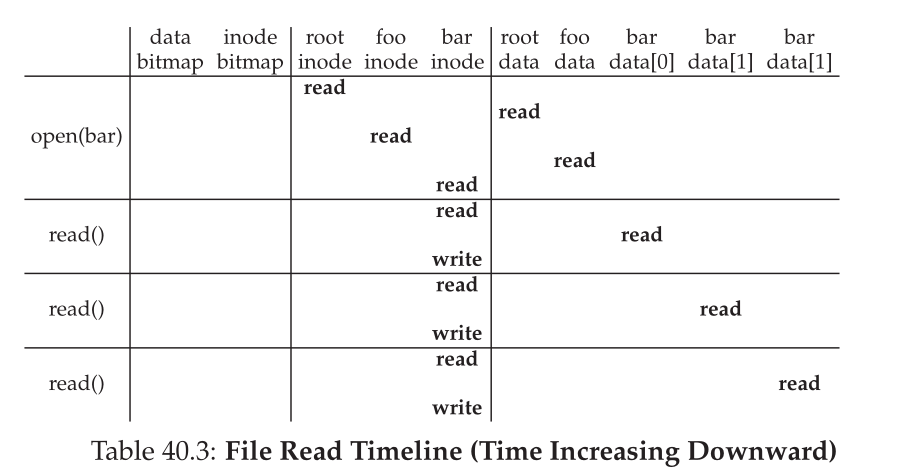
-
Creating a file uses even more IO, requiring reads/writes to the bitmap & updaing directory entries
-
Caching to improve read perf, buffering to improve write perf
-
Databases use manual fsync or direct IO (no page cache) for better persistence guarantee
-
Split the disk into groups (cylinder groups/block groups), each with the same structure as above (superblock, inodes, etc.)
- IO across a single group is faster than IO across multiple (especially far-apart) groups because of rotational/seek costs
- Large files are split across groups so as not to affect the locality benefits
- Less efficient but can come fairly close if the chunk size is chosen carefully
-
- Crash consistency
- As an example, say a file already exists, and uses up one data block
-

- You then append to the file, causing it to spill into a second data block
-
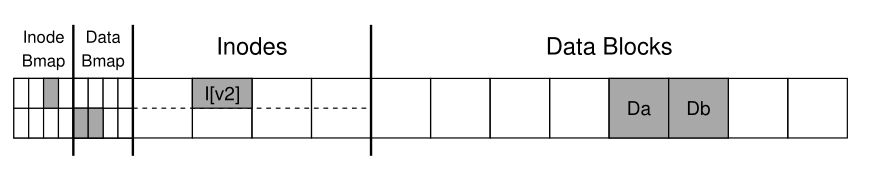
- This requires three separate writes to the disk: update the data bitmap, update the inode, and update the new data block
- What happens if not all writes succeed, but some do?
- Each of these updates first sits in dirty page cache pages, to make things harder
-
- It’s possible for the bitmaps, inodes and data blocks to become inconsistent during a crash
- fsck
-
Allows inconsistencies, fixes them at reboot time
-
Can’t detect some scenarios: inode pointing to garbage data because the data block wasn’t written in time
-
If an allocated inode is discovered but no directory refers to it, it is moved to the lost+found directory.
-
Slow and wasteful
-
- WAL/Journaling
- WAL entries must be atomic (at least logically)
- ext3 has multiple block groups, and a single global journal
- Journal write -> journal commit -> write to disk (checkpoint)
- Need to
fsyncafter the journal write - How are WAL entries garbage collected?
- Implemented as a ring buffer, so older entries are implicitly overwritten
- Metadata journaling
- Only changes to metadata structures (inodes, bitmaps) go in the journal
- Faster, less robust
- Requires that data blocks are written to disk before the metadata WAL entry is committed, so it doesn’t end up pointing to garbage data
- As an example, say a file already exists, and uses up one data block
- LSM filesystems
-
Turn all writes into sequential writes
-
Buffer writes in memory, flush to disk occasionally
-
Also append to a WAL (which is sequential) for crash consistency
-
Existing blocks are never overwritten
-
Optimized for write-heavy workloads *
Memory sizes were growing: As memory got bigger, more data could be cached in memory. As more data is cached, disk traffic would increasingly consist of writes, as reads would be serviced in the cache. Thus, file system performance would largely be determined by its performance for writes.
-
Start reading at a known checkpoint region, which points to the latest version of a given inode
-
ZFS and btrfs use some version of this strategy
-
- Data integrity
- Disks don’t just fail binarily (works/doesn’t work), but may mostly work (sector errors, block corruption)
- Hardware/firmware detects sector errors, use checksums to detect corruption
{kind=link}
Distributed Systems
- RPC-over-TCP is inefficient; RPC is synchronous, and ACKs are required both on the TCP layer and the RPC layer
- NFS (v2)
- The protocol is stateless, the client-side library keeps track of things like FDs and translates them to NFS block numbers/etc.