Linux Page Cache Mini Book
-
/toolsinside a kernel checkout is a thing, especially/tools/vm -
syncto flush dirty pages to disk -
if your write is smaller than the page size, the kernel will read the entire page before your write can be finished.
- An entire page is read from disk, but also an entire cache line is read to L1/2/3
-
sendfile copies data between two FDs entirely in kernel space
-
fsync to flush an fd, msync to sync an mmap pointer, fdatasync to fsync without syncing metadata unless required
- Open a file with
O_SYNCto have the kernel fsync automatically on write.O_DSYNCis similar but uses fdatasync instead - Filesystems may reorder writes, so concurrent mutations with fsync enabled could be unsafe.
- Appends are generally safer
- Open a file with
-
pcstat/vmtouch to check how much of a file has been cached
-
The kernel performs readahead and loads more than one page into memory even if <4KB is requested
- Use
posix_fadviseto change this behavior, alsoreadahead(2) madviseto do this for mmap
- Use
-
I tried this, reading the first 2 bytes of a multi-mb file
- Linux reads 12 pages by default, and a single page with POSIX_FADV_RANDOM
- Linux reads 32 pages by default for an mmap’ed region, and a single page with MADV_RANDOM
-
Use
/sys/fs/cgroup/<cgroup_name>/memory.statto see the number of dirty pages in a cgroup (grep dirty)- /proc/self/cgroup for the current cgroup (everything is in a cgroup?)
- /proc/meminfo is fine, but the cgroup granularity is often very useful
- /proc/
/smaps shows the dirty pages per VM area - “Shared_Dirty” is the size of dirty pages that were dirtied by other processes, but only for pages that the process in question has added to it’s page table
-
Use /proc/PID/pagemap to list page status per (mapped) file
- translate virt->phy addresses
- use physical addresses to index into /proc/kpageflags
-
the
page-typestool in the kernel source (tools/vm/page-types) can do this for you, it spits out something like❯ sudo page-types -f /games/file1.db /games/file1.db Inode: 12 Size: 134217728 (32768 pages) Modify: Fri Jul 1 00:29:00 2022 (1 seconds ago) Access: Fri Jul 1 00:28:18 2022 (43 seconds ago) flags page-count MB symbolic-flags long-symbolic-flags 0x0000000000000028 2047 7 ___U_l______________________________________ uptodate,lru 0x000000000000002c 30696 119 __RU_l______________________________________ referenced,uptodate,lru 0x000000000000003c 1 0 __RUDl______________________________________ referenced,uptodate,dirty,lru 0x0000000000000078 16 0 ___UDlA_____________________________________ uptodate,dirty,lru,active 0x000000000000007c 8 0 __RUDlA_____________________________________ referenced,uptodate,dirty,lru,active total 32768 128 -
how does pcstat/vmtouch figure out how many pages of a file are cached? the
mincoresyscall -
Use cgroups to (effectively) partition the cache
- If processes in two different cgroups read the same file, are cache pages duplicated?
-
Each cgroup has two pairs (active/inactive) of page lists, one for anon pages and one for file pages
- One pair of lists per NUMA node to reduce lock contention across nodes
- More here: BookLinux Kernel Development > Chapter 16 The Page Cache and Page Writeback
-
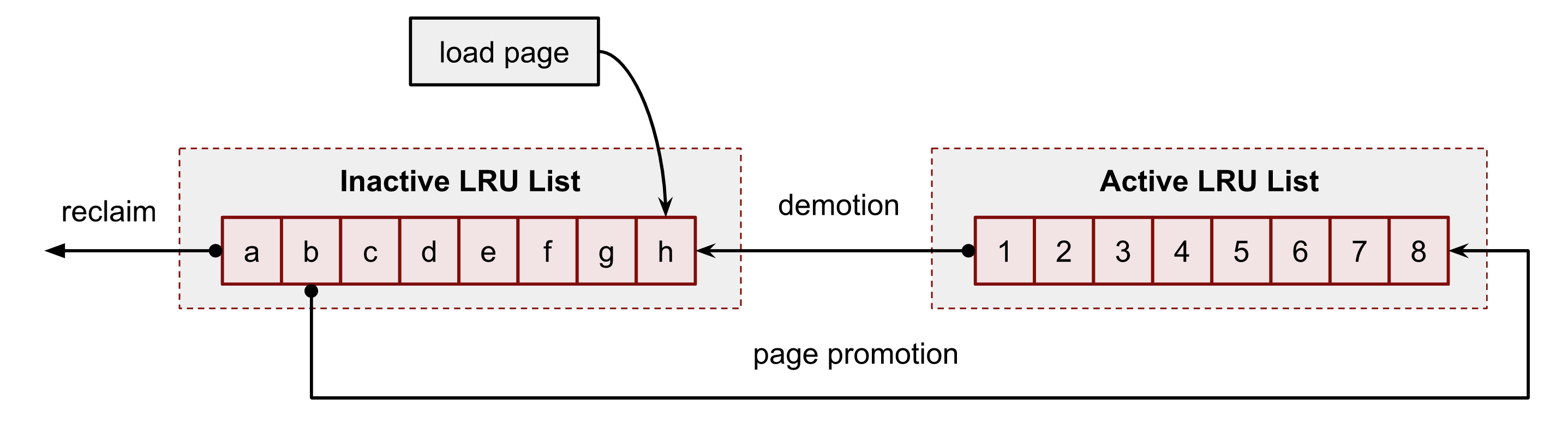
- Each list is a fixed-size FIFO queue
- New pages go to the head of the inactive list
- Accessing an inactive page moves it to the head of the active list, which (if the active list is full) pushes one page down into the inactive list
- Accessing an active page moves it to the head of the active list
- Reclaim starts scanning at the tail of the inactive list
- The source has a great explanation of this mechanism: https://github.com/torvalds/linux/blob/9b30161/mm/workingset.c
-
Refault distance
- Problem: If all the active pages stop being used, but a new workload starts that sequentially faults in more pages than the inactive list has space for, each such page will be evicted from the inactive list before it is accessed a second time, and so won’t ever go on the active list. The active list is full of entries that aren’t required anymore, so this is a problem (assuming the current working set is bigger than the inactive list but also smaller than total RAM)
- Every time an inactive page is accessed, either zero or one pages are evicted (first access), or a page is activated (second access)
- Comparing the number of evictions+activations in an interval provides a minimum bound for the number of inactive page accesses that happened during that interval. If the interval is the time between a page being evicted and refaulted, this is the refault distance.
- Refault distance: (a min. bound for) the number of inactive page accesses that occurred between the time a page was evicted and the time it was refaulted
- If the refault distance is smaller than the size of the active list, then we could probably avoid a ton of refaulting by purging the active list.
- So in this case the refaulting page is activated optimistically to prevent a second refault
- Implementation:
- Each pair of lists stores the number of evictions+activations in memory (node->nonresident_age)
- When a page is evicted, save the current nonresident_age in the “page cache slot of the evicted page”
- This is called a shadow entry
- I think this means that it’s saved in the
struct pageentry that no longer has a physical frame to back it. Thestruct pageentry is still in memory though, and this metadata is available if/when the page is refaulted
- If the page is refaulted, compare nonresident_age at eviction time to refault time. If it’s smaller than the size of the active list, activate the refaulting page
-
“Referenced”
-
Pages aren’t just active/inactive (that was a simplification)
-
Instead there’s a second flag: a page is either “referenced” or “unreferenced”
-
From
swap.c:/* * inactive,unreferenced -> inactive,referenced * inactive,referenced -> active,unreferenced * active,unreferenced -> active,referenced */aa -
The
PG_REFERENCEDflag can be set/cleared by hardware -
Does this mean pages are always acis tivated on the third access, not the second?
- Testing locally, if I read 100MB (worth of pages) into memory, those pages start off referenced+inactive
- And move to unreferenced+active on a second read
- And move to referenced+active on a third
❯ ./cache && sudo page-types -f /games/file1.db 25632 of 32768 pages cached in memory /games/file1.db Inode: 12 Size: 134217728 (32768 pages) Modify: Fri Jul 1 17:10:02 2022 (306 seconds ago) Access: Fri Jul 1 17:10:26 2022 (282 seconds ago) flags page-count MB symbolic-flags long-symbolic-flags 0x000000000000000c 4 0 __RU________________________________________ referenced,uptodate 0x0000000000000028 21 0 ___U_l______________________________________ uptodate,lru 0x000000000000002c 25606 100 __RU_l______________________________________ referenced,uptodate,lru 0x0000000000000228 1 0 ___U_l___I__________________________________ uptodate,lru,reclaim total 25632 100 ❯ ./cache && sudo page-types -f /games/file1.db 25632 of 32768 pages cached in memory /games/file1.db Inode: 12 Size: 134217728 (32768 pages) Modify: Fri Jul 1 17:10:02 2022 (310 seconds ago) Access: Fri Jul 1 17:10:26 2022 (286 seconds ago) flags page-count MB symbolic-flags long-symbolic-flags 0x0000000000000028 21 0 ___U_l______________________________________ uptodate,lru 0x000000000000002c 1 0 __RU_l______________________________________ referenced,uptodate,lru 0x0000000000000068 25609 100 ___U_lA_____________________________________ uptodate,lru,active 0x0000000000000228 1 0 ___U_l___I__________________________________ uptodate,lru,reclaim total 25632 100 ❯ ./cache && sudo page-types -f /games/file1.db 25632 of 32768 pages cached in memory /games/file1.db Inode: 12 Size: 134217728 (32768 pages) Modify: Fri Jul 1 17:10:02 2022 (430 seconds ago) Access: Fri Jul 1 17:10:26 2022 (406 seconds ago) flags page-count MB symbolic-flags long-symbolic-flags 0x0000000000000028 21 0 ___U_l______________________________________ uptodate,lru 0x000000000000002c 1 0 __RU_l______________________________________ referenced,uptodate,lru 0x0000000000000068 9 0 ___U_lA_____________________________________ uptodate,lru,active 0x000000000000006c 25600 100 __RU_lA_____________________________________ referenced,uptodate,lru,active 0x0000000000000228 1 0 ___U_l___I__________________________________ uptodate,lru,reclaim total 25632 100- According to this page, active pages that on the verge of being deactivated are instead pushed to the top of the active list if they’re referenced
-
-
vmtouch can evict all pages for a single file (-e)
- Implemented by passing
POSIX_FADV_DONTNEEDtofadvise
- Implemented by passing
-
mlock, mlock2, and mlockall to lock pages in memory
ulimit -lto change the amount of memory that can be locked (per-process?)ulimit -ato see all ulimit flags- use
/sys/fs/cgroup/CGROUP_NAME/memory.statto find the number of locked pages per cgroup (grep unevictable)
-
The
vm.swappinessoption controls which LRU cache (anon vs file-backed) the kernel prefers to evict from- min 0, max 200, default 60
- value 100: either cache is equally likely to be picked
- not guaranteed to be applied, anon memory is sometimes not touched (regardless of swappiness) if the file cache has a large enough inactive list
- cgroupv2 has separate knobs for this:
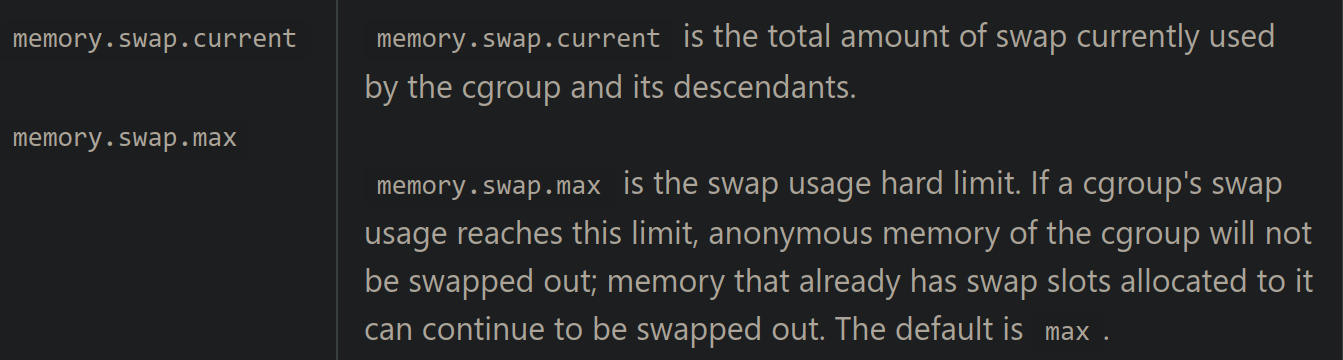
-
/proc/PID/pagemap
- Kernel doc: https://www.kernel.org/doc/Documentation/vm/pagemap.txt
page-types -lto list each page in the page map
-
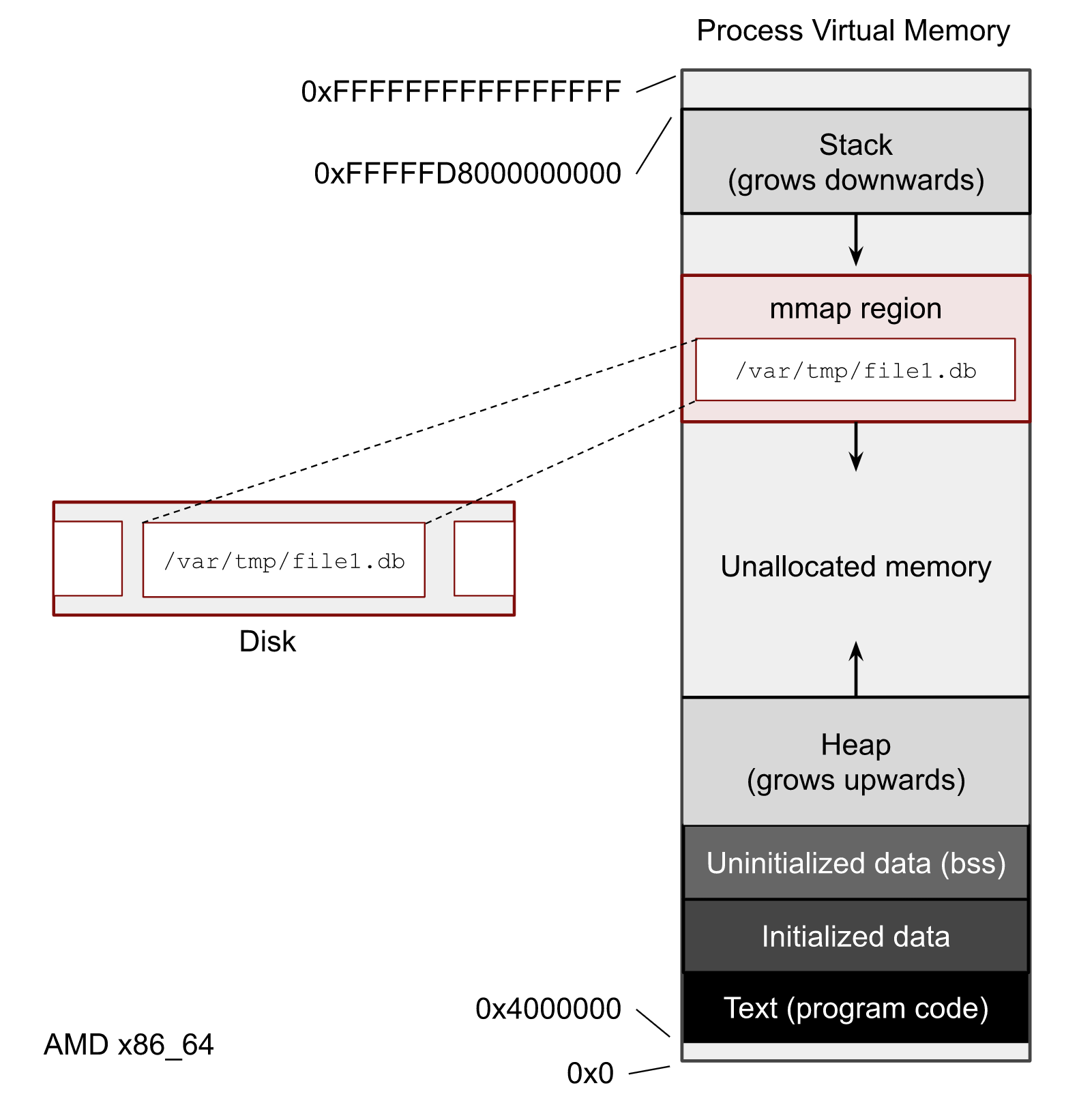
mmap
-
-
Page faults
- major vs minor: major faults need to hit disk, minor faults don’t
- Minor faults are triggered when a process hasn’t previously used a page but the page is already in the page cache
- Minor faults add pages from the page cache into the process' page table
sar -Bfor metrics at this granularity
- https://www.youtube.com/watch?v=7aONIVSXiJ8
- sudo perf trace -F maj –no-syscalls to just major faults
- majflt/s in
sar -Boutput looks suspiciously quiet on my machine, though - use
/sys/fs/cgroup/CGROUP_NAME/memory.statto find a per-cgroup number of faultsA
- major vs minor: major faults need to hit disk, minor faults don’t
-
cgroupv2
- systemd runs each service in a separate cgroup
systemd-cgtopandsystemd-cgls- below: https://github.com/facebookincubator/below
- docs: https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html#usage-guidelines
-
cgroup memory controller
-
memory.current: total memory usage, including page cache -
memory.stat: memory statistics, including dirty pages, locked pages, sizes of the LRU lists, and metrics covering refault logic (workingset) -
memory.numa_stat: same, but per NUMA node -
memory.{min,max}: hard limits, OOM killer when the limit is exceeded *memory.minspecifies a minimum amount of memory the cgroup must always retain, i.e., memory that can never be reclaimed by the system. If the cgroup’s memory usage reaches this low limit and can’t be increased, the system OOM killer will be invoked.-
memory.maxis the memory usage hard limit, acting as the final protection mechanism: If a cgroup’s memory usage reaches this limit and can’t be reduced, the system OOM killer is invoked on the cgroup. Under certain circumstances, usage may go over thememory.highlimit temporarily. When the high limit is used and monitored properly,memory.maxserves mainly to provide the final safety net. The default ismax.
-
-
memory.{low,high}: soft limits, throttling when the limit is exceeded *memory.lowis the best-effort memory protection, a “soft guarantee” that if the cgroup and all its descendants are below this threshold, the cgroup’s memory won’t be reclaimed unless memory can’t be reclaimed from any unprotected cgroups.-
memory.highis the memory usage throttle limit. This is the main mechanism to control a cgroup’s memory use. If a cgroup’s memory use goes over the high boundary specified here, the cgroup’s processes are throttled and put under heavy reclaim pressure. The default ismax, meaning there is no limit.
-
-
memory.events: how often these limits were hit -
memory.pressure: PSI statistics - % of time (some, or all) processes were stalled waiting on memory (refaulting, evicting, etc.) -
cgroup IO limits apply to page cache writeback
-
-
sysctl flags to control page cache writeback frequency/thresholds
$ sudo sysctl -a | grep dirty vm.dirty_background_bytes = 0 vm.dirty_background_ratio = 10 vm.dirty_bytes = 0 vm.dirty_expire_centisecs = 3000 vm.dirty_ratio = 20 vm.dirty_writeback_centisecs = 500 vm.dirtytime_expire_seconds = 43200 -
A file can be accessed by processes in multiple cgroups, which quota do the page cache pages for that file count towards?
- Memory usage for each page is “charged” to the cgroup of the process that first faulted it into cache, and this doesn’t change until it’s evicted
- IO quotas for writeback is “charged” to the cgroup of the process that initiated the first writeback, but the kernel can change this at runtime if necessary based on usage
/proc/kpagecgroupmaps each page to an inode representing the cgroup that page’s memory usage is charged to
-
PSI
- Can register for PSI updates by writing a threshold to
/proc/pressure/{cpu,memory,io}or the equivalent cgroup files - And then polling on the open FD
- Can register for PSI updates by writing a threshold to
-
systemd-runto run ad-hoc commands with limits:systemd-run --user -P -t -G --wait -p MemoryMax=12M wget <url> Running as unit: run-u2.service -
How do you figure out how to set memory limits for a cgroup?
- Going by the peak memory usage is potentially wasteful, because a lot of that usage could be page cache that is never touched again, and can be safely evicted
- Use PSI instead. Tighten memory limits until
memory.pressurestarts going up, then loosen a bit and stop there. - https://github.com/facebookincubator/senpai does this automatically
-
IO_DIRECT
-
Requires that in-memory buffers being read to are aligned at (in general but specific filesystems may have different requirements) 512-byte boundaries
- This is because IO isn’t happening in terms of pages anymore, but sectors (and the most common sector size is 512B), and the kernel directly (via DMA) places one or more sectors into the provided buffer
- Not sure I understand this. As long as the page table is still involved, why does it matter where in the virtual address space the physical (multiple of) 512 bytes is mapped?
- Possibly an optimization to avoid crossing virtual page boundaries? https://stackoverflow.com/questions/3470143/memory-alignment
-
Under Linux 2.4 O_DIRECT required 4K alignment, under 2.6 it’s been relaxed to 512B. In either case, it was probably a design decision to prevent single sector updates from crossing VM page boundaries and therefor requiring split DMA transfers. (An arbitrary 512B buffer has a 1/4 chance of crossing a 4K page).
-
Use
posix_memalignto allocate memory, which ensures that the (virtual) address the allocation is placed it is a multiple of the the given alignment setting
-