CRAQ Paper
- CRAQ PDF
- Chain Replication PDF
- Consistent Hashing PDF
- “Chain Replication with Apportioned Queries”
- Stopped at 3
Questions
- GC for object versions?
- What happens if a node goes down in the middle of the chain?
- Is this shard-able?
1. Introduction
-
Our basic approach, an improvement on Chain Replication, maintains strong consistency while greatly improving read throughput.
-
Chain replication is/can be used for object storage
-
The original chain-replication model logically maintains a chain of all nodes storing a given object (KV)
-
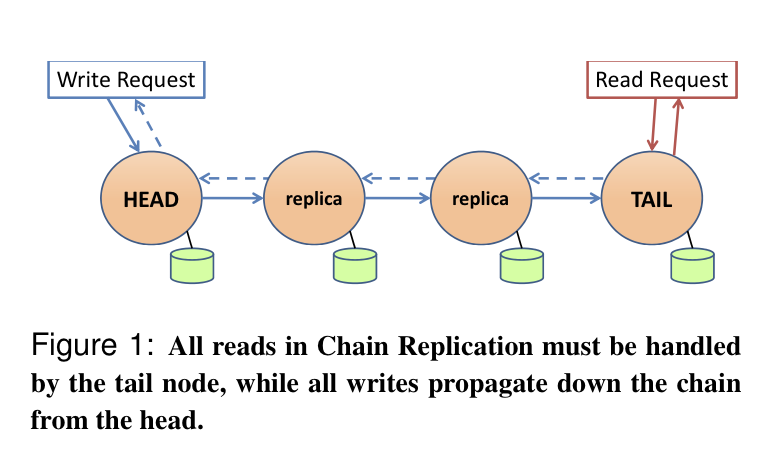
- The head of the chain serves writes, and the write is only successful when the it propagates all the way down the chain.
- The tail of the chain serves reads.
- Read hotspots/bottlenecks
-
-
Apportioned queries refers to dividing (strongly consistent) read operations over all nodes in the chain
-
Performance matches eventually consistent systems for “read-mostly” workloads
-
Consistency level is tunable - you can elect to receive a stale read during times of heavy write contention
-
Uses
PaperZookeeper for deployments
2. Basic System Model
-
Strong consistency: reads & writes are linearizable, reads always see the latest write
-
Eventual consistency: reads can see stale data, but monotonic in the context of a single session with a single node
-
The head accepts writes and propagates them down the chain. It holds the TCP connection open until the tail processes the write, which then sends an ACK back up the chain; the head receives the ACK and then confirms the commit to the client
-
Write throughput is better than other strongly consistent systems, writes are pipelined down the chain, and each node only has to connect to one other node.
-
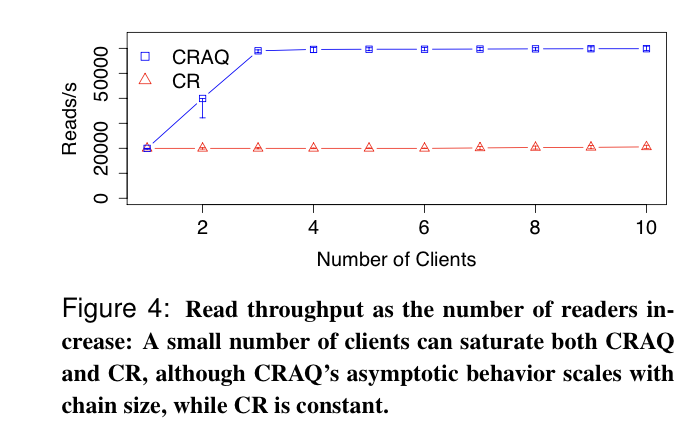
With vanilla chain replication, read throughput is a bottleneck, because all reads have to go to the tail, which is able to build a total ordering over all reads and writes.
-
CRAQ improves read throughput by allowing all nodes to accept reads
- Store multiple versions of each object; monotonic version # and a clean/dirty flag
- During a write, a non-tail node adds a new version for the given object and marks it dirty.
- The tail adds the new version and marks it clean. At this point the new version has been committed
- It then sends the ACK back up the chain, each node sees the ACK and marks the object at that version clean, while deleting all previous versions
- When a node receives a read, it serves the latest version for the object if clean. If not, it asks the tail for the last committed version for that object and serves that instead.
-
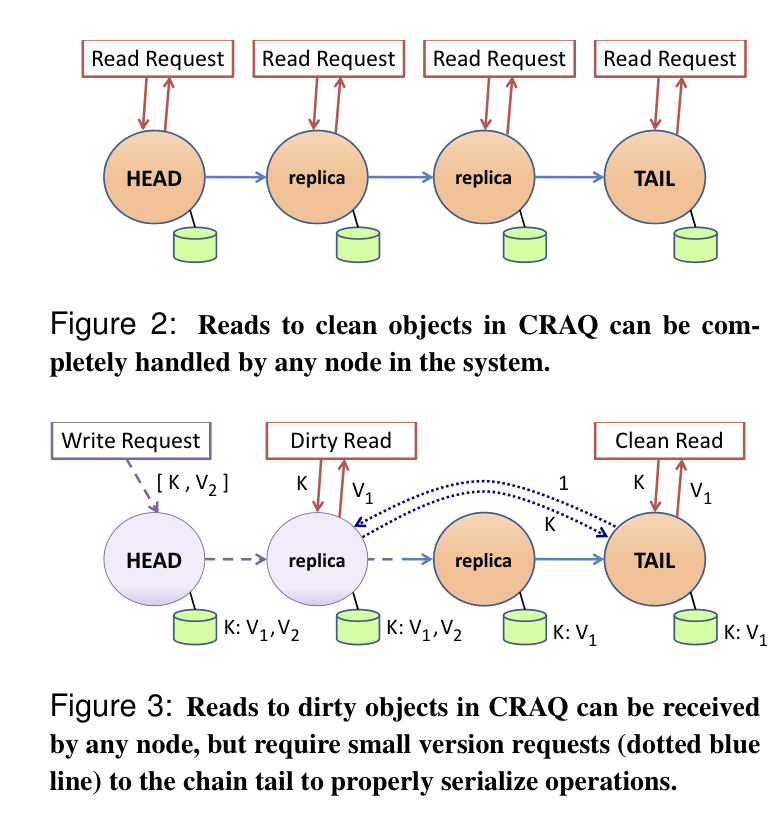
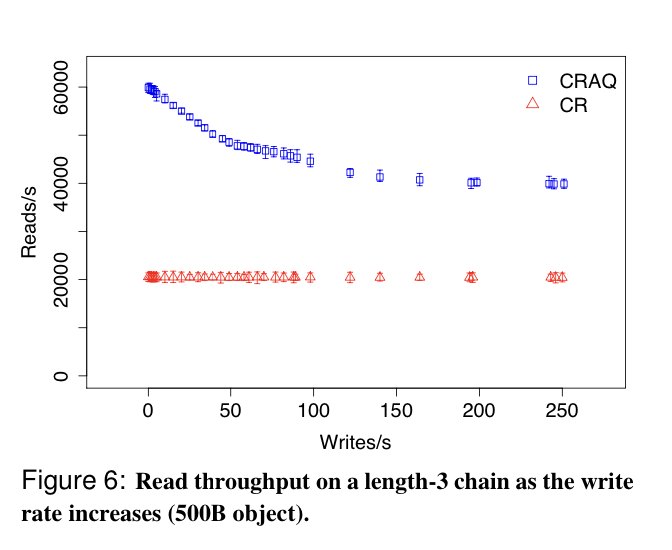
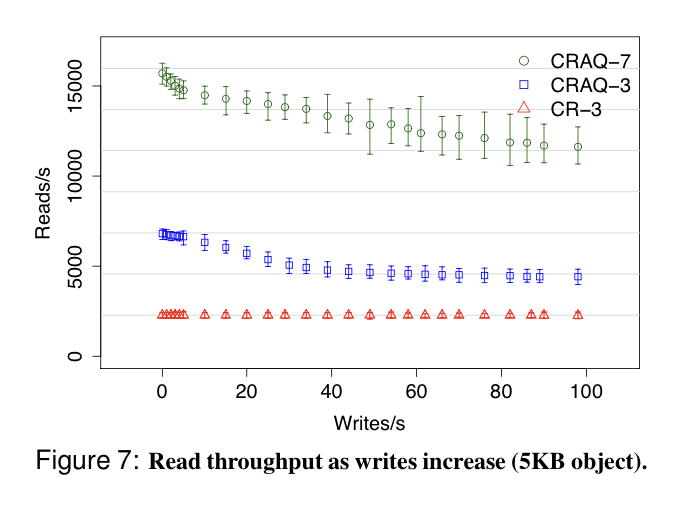
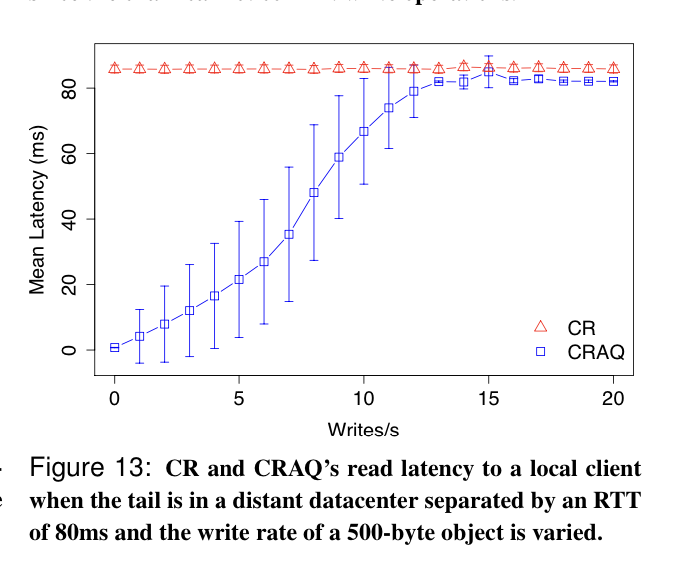
- This is unquestionably a win for read-heavy workloads, but can be better than vanilla CR for write-heavy workloads too, because version requests to the tail are lighter weight than regular reads to the tail.
*
For longer chains that are per- sistently write-heavy, one could imagine optimizing read throughput by having the tail node only handle version queries, not full read requests, although we do not evalu- ate this optimization.
-
Three consistency levels for reads:
- Strong: the default, dirty reads perform a version check against the tail
- Eventual: nodes simply return the latest version for the object, ignoring the clean/dirty status
- Eventual + Bounded: nodes return the latest version for an object, dirty versions are only returned if they’re within a configurable time or version bound (stale by X seconds / stale by X versions).
-
Failure recovery
- All nodes maintain connections (and presumably heartbeats) to adjacent nodes and to the head & tail.
- When a head node fails the next node in line takes over
- When a tail node fails the previous node in line takes over
- When a node is added it inserts itself into the chain like a doubly-linked list
- No real mention of what happens when a node is removed, but according to the CR paper, a separate master service is used to detect failures and remove failed nodes from the chain. The master service uses Paxos/etc. for fault tolerance.
3. Scaling CRAQ
- Configuration options
- A fixed number of datacenters each store a chain, all chains sized the same
- A specific list of datacenters each store a chain, all chains sized the same
- A specific list of datacenters each store a chain, each sized independently
- If I understand correctly, these are all variations of a topology like this, with consistent hashing used against a chain identifier if a list of datacenters/nodes can’t be enumerated in advance:
-
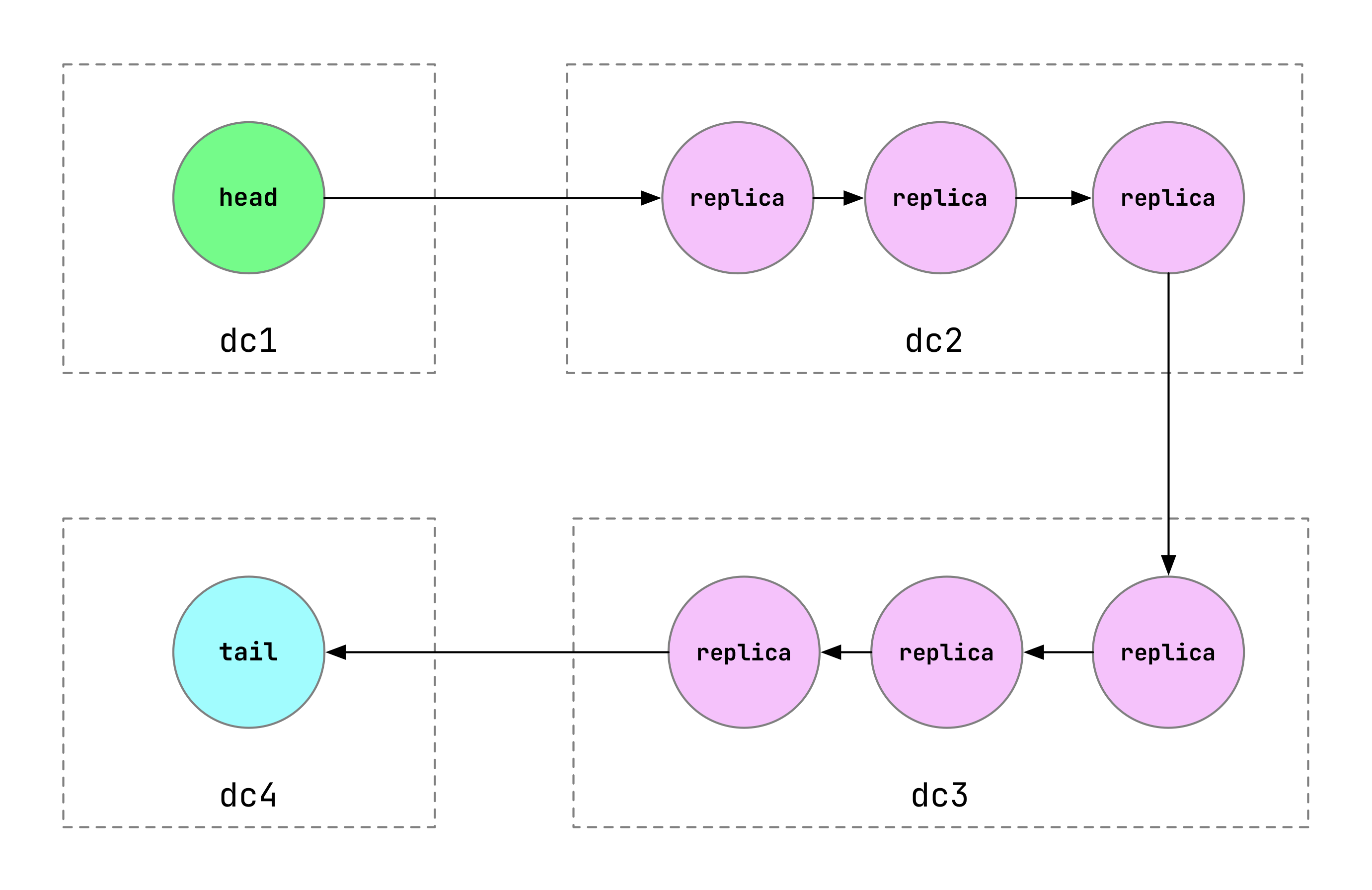
- The paper is a bit light on details, but the chain identifier seems like a way to split a large object space among multiple separate CRAQ chains, with each server node participating in one or more chains.
dc1canbe configured to be the master dc, in which case writes will only ever be accepted indc1, which disables failing over todc2
-
- Uses Zookeeper to store “chain metadata” and “group membership”, but there’s no real explanation of what these things mean in this context.
4. Extensions
- In addition to setting/updating an entire object at once, allow:
- Prepending/appending data
- Increment/decrement
- CAS
- Multiple objects that have the same chain identifier can be written to in a single (mini-)transaction
- CAS and transactions may need to wait at the head node for all uncommitted writes to those objects to be completed (or reject the write)
- Multicast to propagate writes/ACKs in parallel
5. Management and Implementation
-
As described in §3.4, CRAQ needs the functionality of a group membership service.
- WHY?
-
Each node generates a random identifier when joining the system, use consistent hashing to deterministically place it into one (or more?) chains