Crafting Interpreters
Concepts
- A scanner (or lexer) takes in the linear stream of characters and chunks them together into tokens.
- A parser takes the flat sequence of tokens and builds a tree structure that mirrors the nested nature of the grammar.
- A lexical grammar defines how characters are grouped into tokens. A syntactic grammar defines how tokens are grouped into a syntatic structure. A grammar specifies which strings (of characters or tokens) are valid and which aren’t.
- Precedence determines which operator is evaluated first in an expression containing a mixture of different operators.
- Associativity determines which operator is evaluated first in a series of the same operator.
- A parser synchronizes when it hits an error, and moves forward far enough that it can essentially start parsing again with a clean slate (presumably to find errors further on).
Challenges
Answers to a couple of “Challenge” questions at the end of every chapter.
Just-in-time compilation tends to be the fastest way to implement a dynamically typed language, but not all of them use it. What reasons are there to not JIT?
- Slower startup
- Memory overhead
- Implementation complexity
- Sources
The lexical grammars of Python and Haskell are not regular. What does that mean, and why aren’t they?
- According to Wikipedia, a regular language is a language that can be expressed with a regular expression or a deterministic or non-deterministic finite automata or state machine.
- Python’s indentation-based scope can’t be expressed with a regular expression. Haskell uses significant indentation (TIL!) so it’s the same.
Add support for the C-style conditional or “ternary” operator ?:. What precedence level is allowed between the ? and :? Is the whole operator left-associative or right-associative?
I naively assumed “left-associative”, but looking at this, the right-associative version seems a lot more useful:
bare: a == b ? a : b ? c : d
left: (a == b ? a : b) ? c : d
right: (a == b) ? a : (b ? c : d)
Notes
- There’s a whole section on the difference between a compiler and an interpreter which seemed a bit pedantic; I haven’t included any of the highlights from that section here.
Expr.javais generated with a Java script. I used Go instead, but eventually just committed the result and modified it directly.
Highlights
Introduction
Every introduction to every compiler book seems to have this section. I don’t know what it is about programming languages that causes such existential doubt. I don’t think ornithology books worry about justifying their existence.
The designers of the world’s widely-used languages could fit in a Volkswagen bus, even without putting the pop-top camper up. If joining that elite group was the only reason to learn languages, it would be hard to justify. Fortunately, it isn’t.
While academic language folks sometimes look down on object-oriented languages, the reality is that they are widely used even for language work. GCC and LLVM are written in C++, as are most JavaScript virtual machines. Object- oriented languages are ubiquitous and the tools and compilers for a language are often written in the same language.
On self-hosting:
A compiler reads files in one language. translates them, and outputs files in another language. You can implement a compiler in any language, including the same language it compiles, a process called “self-hosting”.
You can’t compile your compiler using itself yet, but if you have another compiler for your language written in some other language, you use that one to compile your compiler once. Now you can use the compiled version of your own compiler to compile future versions of itself and you can discard the original one compiled from the other compiler. This is called “bootstrapping” from the image of pulling yourself up by your own bootstraps.
A Map of the Territory
I find it fascinating that even though today’s machines are literally a million times faster and have orders of magnitude more storage, the way we build programming languages is virtually unchanged.
This is a very helpful analogy, especially on the right side, which I’m not too familiar with. Everything on the left is the “front-end”, and the rest is the “back-end”:
I visualize the network of paths an implementation may choose as climbing a mountain. You start off at the bottom with the program as raw source text, literally just a string of characters. Each phase analyzes the program and transforms it to some higher-level representation where the semantics—what the author wants the computer to do—becomes more apparent.
Eventually we reach the peak. We have a bird’s-eye view of the users’s program and can see what their code means. We begin our descent down the other side of the mountain. We transform this highest-level representation down to successively lower-level forms to get closer and closer to something we know how to make the CPU actually execute.
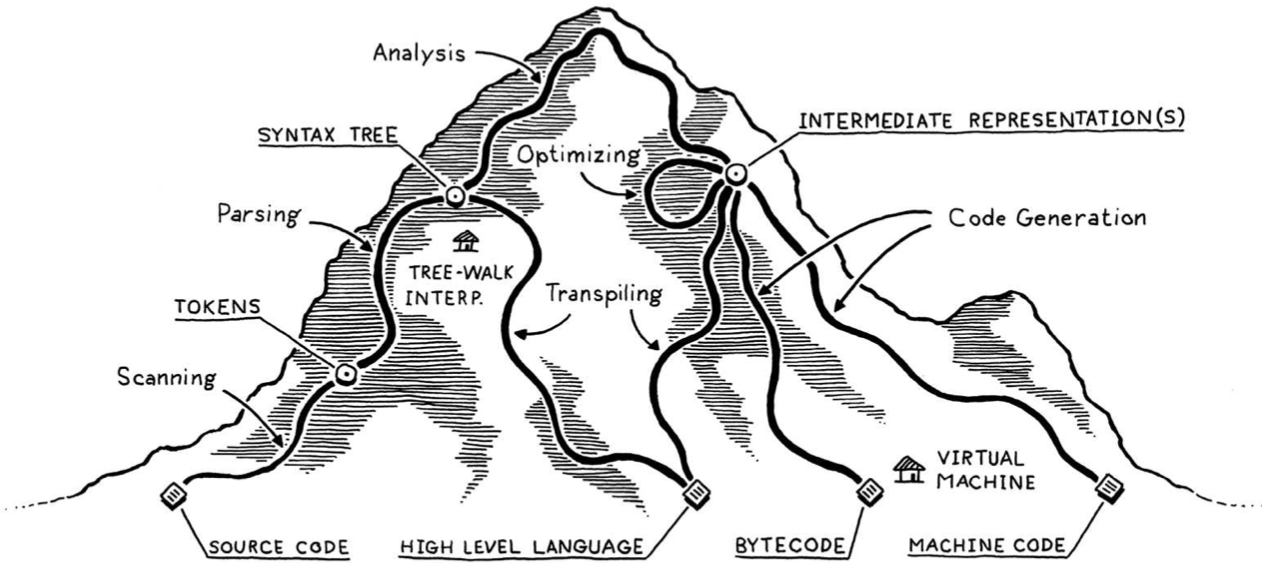
The front end of the pipeline is specific to the source language the program is written in. The back end is concerned with the final architecture where the program will run.
In the middle, the code may be stored in some intermediate representation (or IR) that isn’t tightly tied to either the source or destination forms (hence “intermediate”). Instead, the IR acts as an interface between these two languages.
A shared intermediate representation reduces that (combinatorial explosion of source-target pairs) dramatically. You write one front end for each source language that produces the IR. Then one back end for each target architecture.
Once we understand what the user’s program means, we are free to swap it out with a different program that has the same semantics but implements them more efficiently—we can optimize it.
The farther down the pipeline you push the architecture- specific work, the more of the earlier phases you can share across architectures. There is a tension, though. Many optimizations, like register allocation and instruction selection, work best when they know the strengths and capabilities of a specific chip.
On JITs (apparently HotSpot uses runtime profiling to detect “hot spots” in the bytecode, and incrementally compiles or recompiles those areas with more advanced optimizations):
The fastest way to execute code is by compiling it to machine code, but you might not know what architecture your end user’s machine supports. What to do?
You can do the same thing that the HotSpot JVM, Microsoft’s CLR and most JavaScript interpreters do. On the end user’s machine, when the program is loaded—either from source in the case of JS, or platform-independent bytecode for the JVM and CLR—you compile it to native for the architecture their computer supports. Naturally enough, this is called just-in-time compilation. Most hackers just say “JIT”, pronounced like it rhymes with “fit”.
The Lox Language
There are two main techniques for managing memory: reference counting and tracing garbage collection. Ref counters are much simpler to implement—I think that’s why Perl, PHP, and Python all started out using them. But, over time, the limitations of ref counting become too troublesome. All of those languages eventually ended up adding a full tracing GC or at least enough of one to clean up object cycles.
An expression followed by a semicolon (;) promotes the expression to statement-hood.
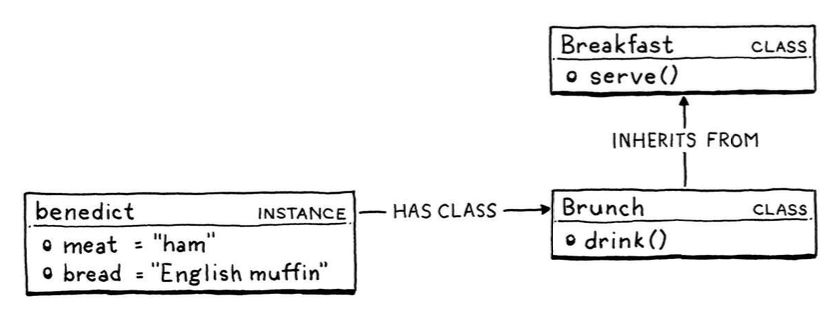
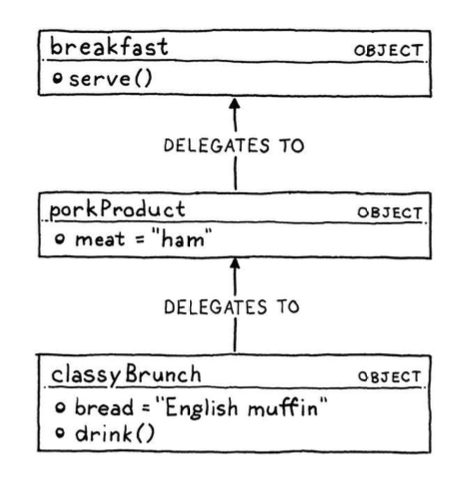
Classes vs. Prototypes:
In a class-based language, there are two core concepts: instances and classes. Prototype-based languages merge these two concepts. There are only objects—no classes—and each individual object may contain state and methods.
Scanning
Way back when computers were as big as Winnebagos but had less memory than your watch, some people used “scanner” only to refer to the piece of code that dealt with reading raw source code characters from disk and buffering them in memory. Then “lexing” was the subsequent phase that did useful stuff with the characters. These days, reading a source file into memory is trivial, so it’s rarely a distinct phase in the compiler. Because of that, the two terms are basically interchangeable.
… an important principle called maximal munch. When two lexical grammar rules can both match a chunk of code that the scanner is looking at, whichever one matches the most characters wins.
Representing Code
A regular grammar can repeat, but it can’t count.

The Visitor Pattern
This was an interesting digression - OO languages tend to allow you to group all operations on a type in a single entity (a class), represented by a single row. ML languages tend to allow you to group all types that an operation can act on in a single entity (a pattern match). We really want the latter here to avoid polluting the Expr classes with implementation details. This isn’t natively possible in Java, but the Visitor Pattern is a good way to get around it.
If I understood the pattern correctly:
- Every operation you want to perform on a tree of types gets its own class, implementing a
Visitorinterface. - The interface contains one method for each concrete type in the tree of types.
- Given an instance from the tree of types, and a visitor class, you apply the visitor to the instance with - instance.accept(visitor) - which calls the right method on the visitor.
- A given implementation of
Visitorencapsulates a single operation that can be applied to any type in the tree of types.
Parsing Expressions
The top expression rule matches any expression at any precedence level. Since equality has the lowest precedence, if we match that, then it covers everything:
There is a whole pack of parsing techniques whose names are mostly combinations of “L” and “R”—LL(k), LR(1), LALR—along with more exotic beasts like parser combinators, Earley parsers, the shunting yard algorithm, and packrat parsing. For our first interpreter, one technique is more than sufficient: recursive descent.
It’s called “recursive descent” because it walks down the grammar. Confusingly, we also use direction metaphorically when talking about “high” and “low” precedence, but the orientation is reversed. In a top-down parser, you reach the lowest-precedence expressions first because they may in turn contain subexpressions of higher precedence.
CS people really need to get together and straighten out their metaphors. Don’t even get me started on which direction a stack grows or why trees have their roots on top.

GCC, V8 (the JavaScript VM in Chrome), Roslyn (the C# compiler written in C#) and many other heavyweight production language implementations use recursive descent. It rocks.
Recursive descent is considered a top-down parser because it starts from the top or outermost grammar rule (here expression) and works its way down into the nested subexpressions before finally reaching the leaves of the syntax tree.
Error Recovery
As soon as the parser detects an error, it enters panic mode. Before it can get back to parsing, it needs to get its state and the sequence of forthcoming tokens aligned such that the next token does match the rule being parsed. This process is called synchronization. The traditional place in the grammar to synchronize is between statements.
Another way to handle common syntax errors is with error productions. You augment the grammar with a rule that successfully matches the erroneous syntax. The parser safely parses it but then reports it as an error instead of producing a syntax tree.
Evaluating Expressions
In Lox, values are created by literals, computed by expressions, and stored in variables. The user sees these as Lox objects, but they are implemented in the underlying language our interpreter is written in. That means bridging the lands of Lox’s dynamic typing and Java’s static types
The rest of this section was fairly straightforward; definitely the first time through this book that I didn’t feel completely lost. You end up with an interpreter that can do things like this: