Apache Kafka Needs No Keeper - Removing the Apache ZooKeeper Dependency
https://www.confluent.io/blog/removing-zookeeper-dependency-in-kafka/
- Kafka is removing its Zookeeper dependency, switching (optionally) to storing metadata internally, in a Kafka partition.
- There’s a bit of a chicken-and-egg problem here, which is resolved by a builtin Raft implementation solely for consensus around this metadata.
- Apart from removing significant ops overhead, another bonus with this design is much faster maintentance operations.
So what is the problem with ZooKeeper? Actually, the problem is not with ZooKeeper itself but with the concept of external metadata management.
Having two systems leads to a lot of duplication. Kafka, after all, is a replicated distributed log with a pub/sub API on top. ZooKeeper is a replicated distributed log with a filesystem API on top. Each has its own way of doing network communication, security, monitoring, and configuration. Having two systems roughly doubles the total complexity of the result for the operator. This leads to an unnecessarily steep learning curve and increases the risk of some misconfiguration causing a security breach.
KIP-500 outlines a better way of handling metadata in Kafka. You can think of this as “Kafka on Kafka,” since it involves storing Kafka’s metadata in Kafka itself rather than in an external system such as ZooKeeper. In the post-KIP-500 world, metadata will be stored in a partition inside Kafka rather than in ZooKeeper.
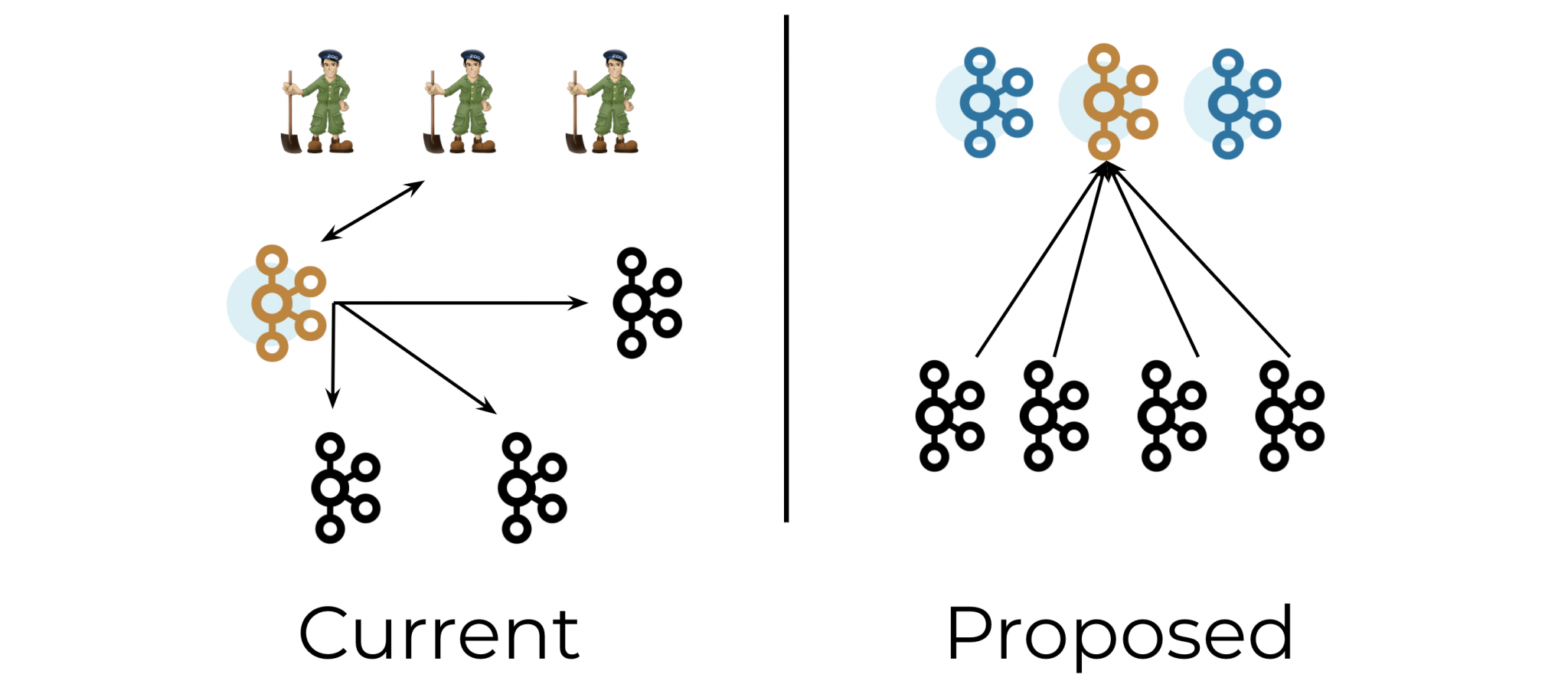
In the post-KIP-500 world, the Kafka controller will store its metadata in a Kafka partition rather than in ZooKeeper. However, because the controller depends on this partition, the partition itself cannot depend on the controller for things like leader election. Instead, the nodes that manage this partition must implement a self-managed Raft quorum.
In the post-KIP-500 world, the Kafka controller will store its metadata in a Kafka partition rather than in ZooKeeper. However, because the controller depends on this partition, the partition itself cannot depend on the controller for things like leader election. Instead, the nodes that manage this partition must implement a self-managed Raft quorum.